De l'évaluation aux données d'entraînement : l'édition de trajectoires pour le SFT et le DPO
La plupart des évaluations d'agents s'arrêtent à un score. Le schéma trajectory_edit de Potato 2.6 permet aux annotateurs de réécrire une étape erronée plutôt que de la noter, et exporte chaque correction sous forme de cibles de fine-tuning supervisé et de paires de préférence pour le DPO.
L'évaluation d'un agent se termine généralement par un nombre. Un annotateur lit une trajectoire, conclut que la troisième étape était fausse, puis enregistre un score faible ou attribue un type d'erreur. Ce nombre est utile pour mesurer la fréquence des échecs de l'agent. Il l'est beaucoup moins pour le corriger, car « la troisième étape était fausse » ne dit pas au modèle ce qu'aurait dû être la troisième étape.
La prochaine version Potato 2.6 ajoute un schéma qui demande la réponse plutôt que la note. Avec trajectory_edit, les annotateurs réécrivent les étapes d'un agent trace (trace d'agent) : ils corrigent une étape de raisonnement ratée, réparent une tool call (appel d'outil) mal saisie ou renforcent une réponse finale faible, et Potato conserve la trajectoire corrigée à côté de l'originale. L'exportateur trajectory_correction transforme ensuite chaque paire (original, corrected) en données d'entraînement : des cibles de fine-tuning supervisé et des paires de préférence pour l'optimisation directe des préférences.
C'est de ce basculement que parle cet article. Il transforme un outil d'évaluation en un outil de production de données d'entraînement, et change ce que produit le temps d'un annotateur humain : non plus une étiquette, mais un signal d'apprentissage.
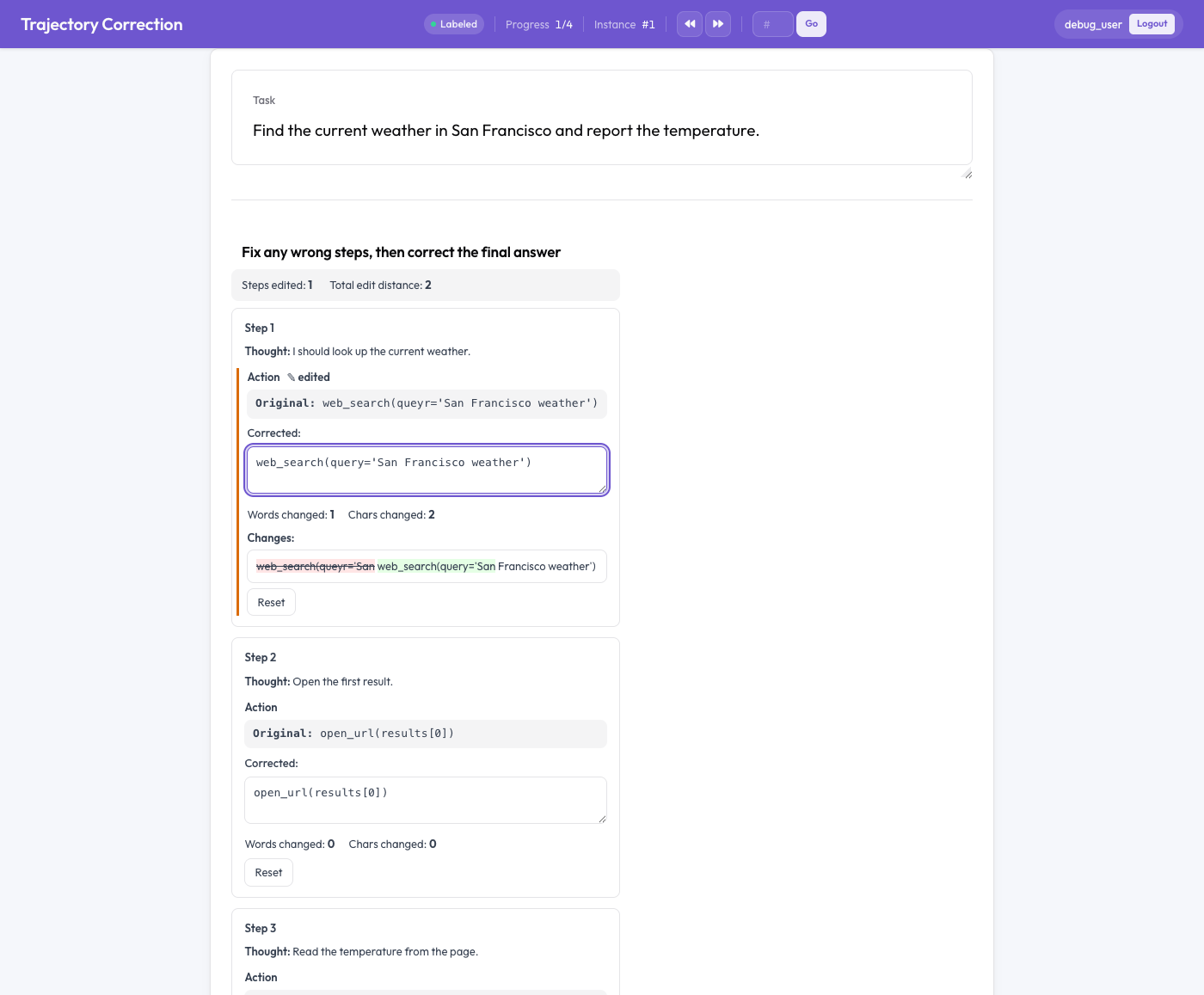 L'éditeur de correction de trajectoires
L'éditeur de correction de trajectoires
Éditer plutôt que noter
Chaque étape de l'agent s'affiche sous forme de carte en deux moitiés : le texte original, en lecture seule, et un encadré corrigé éditable prérempli avec l'original. L'annotateur édite directement l'encadré corrigé. À mesure qu'il saisit, trois choses se produisent :
- un diff en direct au niveau du mot met en évidence les insertions en vert et les suppressions en rouge barré,
- les mots et les caractères modifiés sont comptés, et
- un indicateur « edited » (édité) apparaît sur tout champ ayant changé.
Un bouton « Reset » rétablit l'original d'un champ si l'annotateur change d'avis. Point essentiel : rien n'est obligatoire. Un annotateur qui lit une trace et la juge correcte la laisse simplement telle quelle, et une trace non éditée ne produit aucune paire d'entraînement. Le signal ne provient que de corrections réelles.
Configuration
Le schéma pointe vers la liste d'étapes de vos données et indique quels champs sont éditables :
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerPar défaut, seule l'action de chaque étape est éditable. Ajoutez thought à editable_fields lorsque vous voulez que les annotateurs réparent le raisonnement de l'agent en plus de ses actions, et définissez require_reason_on_edit: true lorsque vous voulez qu'une justification écrite soit jointe à chaque modification, ce qui est utile lorsque les corrections elles-mêmes seront relues.
Le format des données est exactement celui que vos traces ont déjà. Le schéma lit les étapes depuis le champ désigné par steps_key ; chaque étape est un objet dont les champs peuvent être édités :
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}La faute de frappe dans queyr est exactement le genre de chose qu'un annotateur corrige dans l'encadré corrigé, produisant une correction d'un seul token dont le modèle peut apprendre.
Lancez l'exemple fourni depuis la racine du dépôt :
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Des corrections aux fichiers d'entraînement
L'exportateur trajectory_correction écrit trois fichiers, chacun pour un usage en aval distinct :
trajectory_corrections.jsoncontient l'enregistrement complet : l'original_trace, lecorrected_tracereconstruit et leseditspar champ avec distances d'édition et motifs. C'est votre piste d'audit.trajectory_sft.jsonlcomporte une ligne par trace éditée,{"prompt": <task>, "completion": <corrected_trace>}. La trajectoire corrigée devient la cible qu'un modèle est fine-tuné pour reproduire.trajectory_dpo.jsonlcomporte une ligne par trace éditée,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. L'édition de l'humain définit la préférence : la version corrigée plutôt que l'originale.
 Comment les éditions deviennent des données d'entraînement SFT et DPO
Comment les éditions deviennent des données d'entraînement SFT et DPO
Le fichier DPO est la partie qui vient gratuitement. Dans un pipeline classique de données de préférence, il faut générer ou collecter une réponse moins bonne à apparier avec la meilleure. Ici, la réponse moins bonne existe déjà (c'est la trajectoire originale produite par l'agent) et l'édition de l'humain prouve que la version corrigée est préférée. Une seule annotation produit à la fois une cible SFT et une paire DPO.
Ce qui est ignoré, et pourquoi cela compte
Les traces non éditées sont comptées mais exclues des fichiers SFT et DPO. S'entraîner sur une trajectoire inchangée n'apprend rien au modèle et, pire, inonderait un jeu de données de préférence de paires chosen == rejected qui ajoutent du bruit. Le décompte des traces ignorées apparaît tout de même dans les statistiques d'export, ce qui vous permet de voir quelle proportion du lot était déjà correcte, signal lui-même utile sur la qualité de l'agent. Avec plusieurs annotateurs, chaque annotateur ayant édité une trace donnée produit un enregistrement SFT/DPO, de sorte que toutes les corrections indépendantes contribuent.
Quelques points épineux
- Le diff est au niveau du mot. Pour des tool calls (appels d'outils) ressemblant à du code et sans espaces, un seul token peut apparaître comme entièrement modifié même pour une correction d'un seul caractère. Le compteur de distance de caractères est le signal précis dans ces cas ; fiez-vous-y plutôt qu'au diff visuel pour les appels d'outils denses.
- L'édition se marie naturellement avec la notation. Si vous voulez aussi des étiquettes de justesse par étape ou une taxonomie d'erreurs sur la même trace, faites tourner un schéma de notation au niveau de l'étape aux côtés de l'éditeur, afin qu'une seule passe produise à la fois le diagnostic et la correction.
Pourquoi cela compte
La boucle d'ajustement des agents a toujours eu un goulot d'étranglement à l'étape « qu'aurait-il dû faire ». Les scores vous disent où un modèle échoue ; ils ne produisent pas le comportement corrigé sur lequel s'entraîner, si bien que les équipes finissent par rédiger des corrections synthétiques ou par payer une seconde passe d'étiquetage. L'édition de trajectoires replie cela dans l'évaluation elle-même. La même personne qui aurait noté la trace la répare à la place, et la réparation est la donnée d'entraînement.
L'édition de trajectoires arrive dans Potato 2.6. Consultez la documentation sur l'édition de trajectoires pour la liste complète des options, l'affichage eval_trace pour lire rapidement les traces avant d'éditer, et la référence des formats d'export pour les détails de l'exportateur.