Le codage qualitatif arrive dans Potato : livres de codes, mémos et codes in vivo
Un aperçu du mode QDA, l'espace de travail d'analyse de données qualitatives à venir dans Potato 2.6 : un livre de codes vivant, du codage in vivo, des mémos analytiques, des cas et une recherche plein texte sur tout un corpus.
Si vous avez déjà codé des retranscriptions d'entretiens, vous connaissez l'histoire du logiciel. Les outils sérieux d'analyse de données qualitatives (QDA), comme NVivo, ATLAS.ti, MAXQDA et Dedoose, sont puissants et coûteux. Ils vivent sur le bureau, enferment votre projet dans un fichier propriétaire et transforment la collaboration en négociation de licences. Beaucoup de chercheurs finissent par coder dans un tableur, puis perdent le fil à mi-parcours, parce qu'un tableur n'a aucune idée de ce qu'est un code.
Potato est né de l'autre côté de la barrière, comme outil d'annotation de texte pour les jeux de données de TAL et d'apprentissage automatique. Au fil des dernières versions, il a développé les pièces qu'exige un flux de travail qualitatif : des empans (spans) sur les passages, un livre de codes partagé, des mesures d'accord. La prochaine version 2.6 les relie en un mode conçu pour la façon dont les chercheurs qualitatifs travaillent réellement.
Cet article parcourt le mode QDA : ce qu'il active, comment les pièces s'emboîtent et à quoi ressemble une configuration. Si vous cherchez la référence, la documentation du mode QDA contient la liste complète des options.
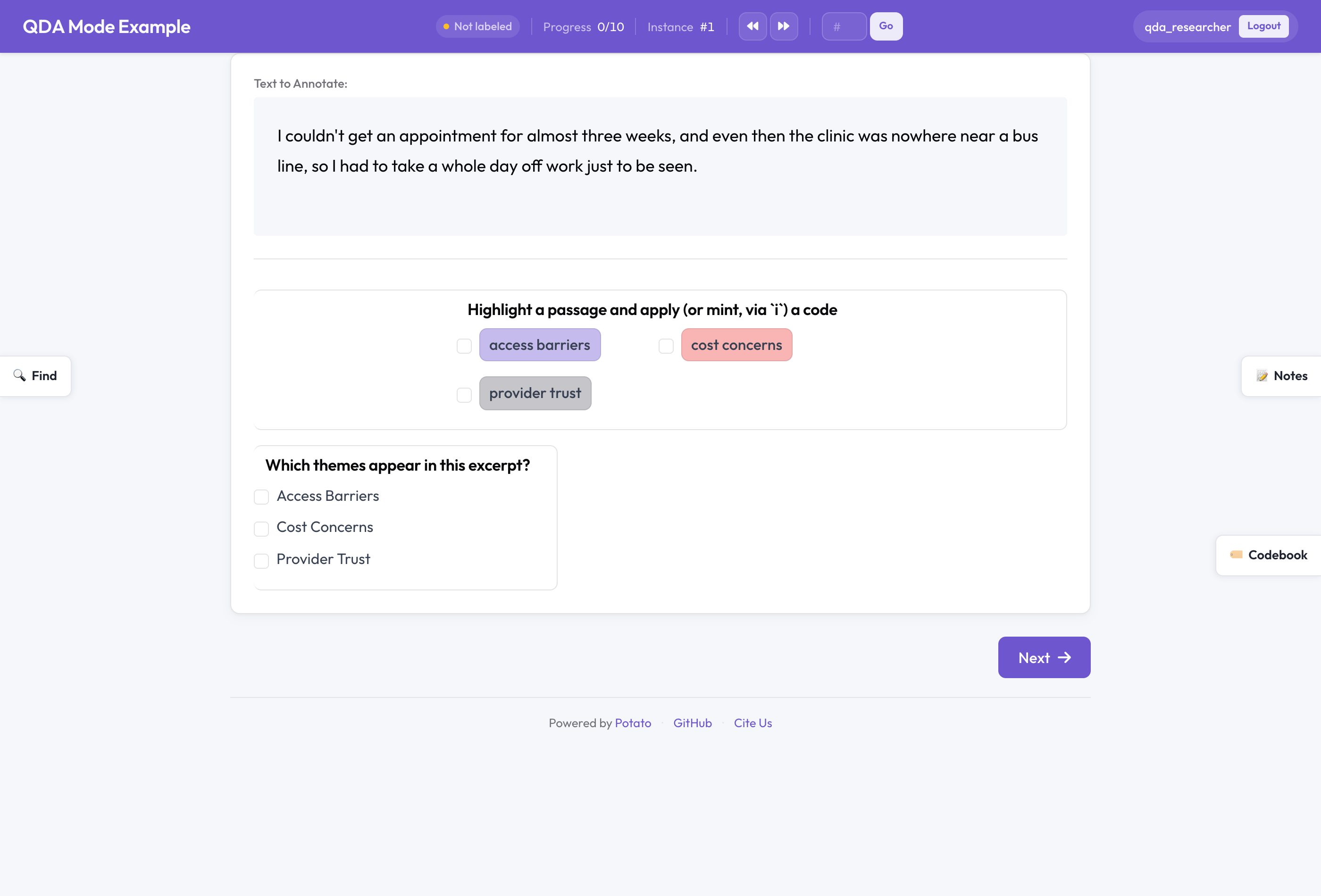 Potato en mode QDA
Potato en mode QDA
Un seul interrupteur, des valeurs qualitatives par défaut
L'essentiel de la mécanique de Potato est partagé entre des tâches très différentes. Le même schéma d'empan qui étiquette les entités nommées d'un jeu de données NER peut étiqueter des passages dans un entretien. La différence entre ces deux travaux n'est pas l'ensemble des fonctionnalités, mais la posture. Un projet NER en crowdsourcing veut un jeu d'étiquettes fixe et un échantillonnage avec recouvrement pour mesurer l'accord. Une chercheuse qui code seule vingt entretiens veut inventer des codes au fil de sa lecture et garder des notes privées sur ce qu'elle observe.
Le mode QDA est l'unique interrupteur qui adopte cette seconde posture :
qda_mode:
enabled: true # compose codebook + memos + cases + searchDéfinir qda_mode.enabled: true bascule les fonctionnalités universelles de Potato vers leurs valeurs qualitatives par défaut. Le livre de codes devient modifiable pendant que vous codez, au lieu d'être verrouillé. La barre latérale des mémos s'active. Les cas s'activent, avec détection automatique. Le codage in vivo devient disponible sur tout schéma d'empan que vous marquez comme adossé au livre de codes.
| Fonctionnalité | Valeur par défaut standard | En mode QDA |
|---|---|---|
| Mode du livre de codes | fixed | open : ajoutez, renommez, recolorez, déplacez ou supprimez des codes au fil de l'eau |
| Barre latérale des mémos | désactivée | activée |
| Cas | désactivés | activés, avec détection automatique |
| Recherche-et-réclamation par annotateur | désactivée | disponible (search.annotator_claim: true) |
| Touche de codage in vivo | i | active sur tout schéma d'empan adossé au livre de codes |
Rien de tout cela n'est figé. Le mode QDA ne change que le point de départ ; chaque valeur par défaut peut être remplacée. La seule exception est un garde-fou : si vous branchez un backend de crowdsourcing comme Prolific ou Mechanical Turk, Potato verrouille de force le livre de codes en fixed, afin que des annotateurs rémunérés ne puissent pas refaçonner le schéma partagé dans votre dos.
Les pièces
Un livre de codes vivant
Dans le codage de type théorie ancrée, le livre de codes n'est pas une chose que vous rédigez à l'avance. Il croît au fil de la lecture. Vous remarquez une idée récurrente, vous la nommez, et une semaine plus tard vous comprenez que deux de vos codes n'en font en réalité qu'un et vous les fusionnez.
Un schéma d'empan devient partie intégrante du livre de codes lorsque vous le marquez :
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Ces labels sont un ensemble de départ, pas une cage. En mode de livre de codes open, vous ajoutez, renommez, recolorez, déplacez et supprimez des codes pendant que vous travaillez. Le mode extensible permet aux codeurs d'ajouter des codes mais pas de supprimer ceux qui sont partagés ; fixed est le classique verrouillé, pour quand vous avez arrêté un schéma.
Codage in vivo
Le codage in vivo prend les propres mots du participant comme code. Quelqu'un dit « je n'arrivais tout simplement pas à être rappelé », et « être rappelé » devient le code, mot pour mot.
Sélectionnez un passage sur un schéma d'empan adossé au livre de codes et appuyez sur la touche in vivo (codebook_invivo_key, i par défaut). Potato forge un code directement à partir du texte surligné. À mesure que vous faites cela sur tout un corpus, la fragmentation devient l'ennemie : vous vous retrouvez avec « pas de rappel », « je n'arrivais pas à être rappelé » et « on ne m'a jamais rappelé » comme trois codes pour une seule idée. Le compositeur de codes contre cela en faisant remonter les codes quasi identiques pendant que vous tapez, pour que vous réutilisiez un code existant au lieu d'en engendrer un autre.
Mémos
Coder sans notes fait perdre le raisonnement derrière les codes. Les mémos sont des notes analytiques rattachées à une instance ou à une sélection de texte précise. Vous pouvez les garder privés ou les partager avec l'équipe. C'est là que vit le « pourquoi ai-je codé cela ainsi », et ils s'exportent aux côtés des citations pour que votre piste d'audit survive au projet.
Cas
Un cas regroupe des extraits en une unité d'analyse : un participant, un document, une visite de terrain. Une fois les extraits regroupés, les attributs au niveau du cas sont remontés afin que vous puissiez tabuler les codes par rapport aux variables des participants. Si chaque entretien porte un champ condition, le tableau croisé d'administration peut montrer comment un code se répartit entre les conditions.
cases:
enabled: true
key: participant_id
attributes: [condition]Recherche
Un corpus n'est navigable que si vous pouvez sauter à n'importe quelle occurrence d'un mot. Le mode QDA comprend la recherche plein texte FTS5 sur l'ensemble du jeu de données. Avec annotator_claim: true, un codeur peut tirer n'importe quel résultat de recherche directement dans sa propre file, et c'est ainsi qu'un analyste seul parcourt un corpus par thème plutôt que de le lire strictement du début à la fin.
search:
enabled: true
annotator_claim: trueComment tout s'articule
Sous le capot, le livre de codes, les mémos, les cas et la recherche lisent et écrivent dans la même base de données de projet, de sorte qu'un code forgé à un endroit devient immédiatement recherchable et exportable partout ailleurs.
 Comment le mode QDA compose ses pièces au-dessus d'un magasin partagé
Comment le mode QDA compose ses pièces au-dessus d'un magasin partagé
Une configuration complète
Voici une étude petite mais complète. Les blocs cases, search et mémos sont facultatifs (le mode QDA active déjà les cas et les mémos), vous ne les écrivez donc que pour régler une valeur par défaut comme la clé de cas.
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]Lancez-la depuis la racine du dépôt une fois la 2.6 installée :
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000Récupérer votre codage
Deux exportateurs transforment les données codées en livrables dont un article qualitatif a besoin :
codebookdonne une ligne par code, avec sa hiérarchie, sa description, sa couleur et son nombre d'utilisations.quotation_reportdonne une ligne par empan codé : la citation, ses décalages de caractères, l'instance source et le codeur. Ajoutezinclude_memos=truepour y joindre vos mémos.
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvSi plusieurs personnes codent le même matériau, vous voudrez un indice de fiabilité. Potato rapporte les kappa de Cohen et de Fleiss sur les codes, fonctionnalité arrivée dans la version 2.5 aux côtés de ces exportateurs.
Où cela se situe
Le mode QDA ne cherche pas à surclasser NVivo en fonctionnalités sur tous les axes. Ce qu'il propose, c'est un compromis différent : gratuit, open source, basé sur le web et collaboratif, logé dans le même outil que votre annotation pour l'apprentissage automatique et votre évaluation d'agents. Si votre laboratoire fait déjà tourner Potato pour l'étiquetage, le codage qualitatif n'est plus qu'à un bloc de configuration de distance, et non plus à celle d'un logiciel de bureau sous licence à part.
Le mode QDA est livré dans Potato 2.6. La documentation complète couvre chaque option, et le guide de l'accord inter-annotateurs explique les mesures de fiabilité.