How to Collect Process Reward Data for Training Better Coding Agents
Step-by-step guide to collecting per-step reward signals for PRM training using Potato. Covers first-error mode, per-step annotation, and export to training pipelines.
What Are Process Reward Models?
 Two ways to label process rewards
Two ways to label process rewards
Outcome reward models (ORMs) look only at the end of a coding agent's trajectory: did the code compile, did the tests pass, was the issue resolved? Process reward models (PRMs) score each intermediate step instead. With a reward signal at every step, training methods can pinpoint where an agent went wrong, which tends to make learning more sample-efficient and helps generalization.
Recent work backs this up. AgentPRM reported that step-level reward signals improve agent performance on SWE-bench by 12-18% over outcome-only supervision. ToolRM found that per-tool-call rewards help agents learn which tools to use when. DeepSWE paired process rewards with Monte Carlo tree search for state-of-the-art results on hard software engineering tasks.
What all of these need is good step-level human annotation, and that's usually the bottleneck. Potato's process reward schemas are built to make collecting that data faster. For the underlying schema, see the trajectory evaluation documentation, and for trace input details, the agent traces documentation.
Two Annotation Modes
Potato has two PRM annotation modes that trade speed for granularity. Pick the one that fits your data budget and goals.
First-Error Mode
In first-error mode, the annotator reads the trajectory from top to bottom and clicks the first step where the agent makes a mistake. Potato then marks every earlier step correct and every step from the clicked one onward incorrect.
This is fast because the annotator only has to find a single decision point. It works well when errors cascade, that is, once an agent goes off track it rarely recovers, which is the common case in practice.
annotation_schemes:
- annotation_type: process_reward
name: prm_first_error
mode: "first_error"
labels:
correct: "Correct"
incorrect: "Incorrect"
description: >
Review the agent's steps from top to bottom. Click on the
first step where the agent makes a mistake. All steps before
your selection will be marked correct; all steps after
(including the selected step) will be marked incorrect.
allow_all_correct: true
allow_all_incorrect: true
highlight_clicked_step: true
auto_scroll_on_click: true
show_step_numbers: true
confirmation_dialog: true # Confirm before submittingThe first-error annotation workflow looks like this:
- The annotator opens a trace and sees all steps rendered with the CodingTraceDisplay component.
- They read through the steps sequentially, examining diffs, terminal outputs, and reasoning.
- When they find the first incorrect step, they click the error marker next to it.
- Steps 0 through N-1 turn green (correct), steps N through the end turn red (incorrect).
- The annotator reviews the automatic labeling and clicks "Submit" to confirm.
If the entire trace is correct (the agent solved the task perfectly), the annotator clicks "All Correct." If the very first step is already wrong, they click step 0 or use "All Incorrect."
Here's the PRM annotation interface in action:
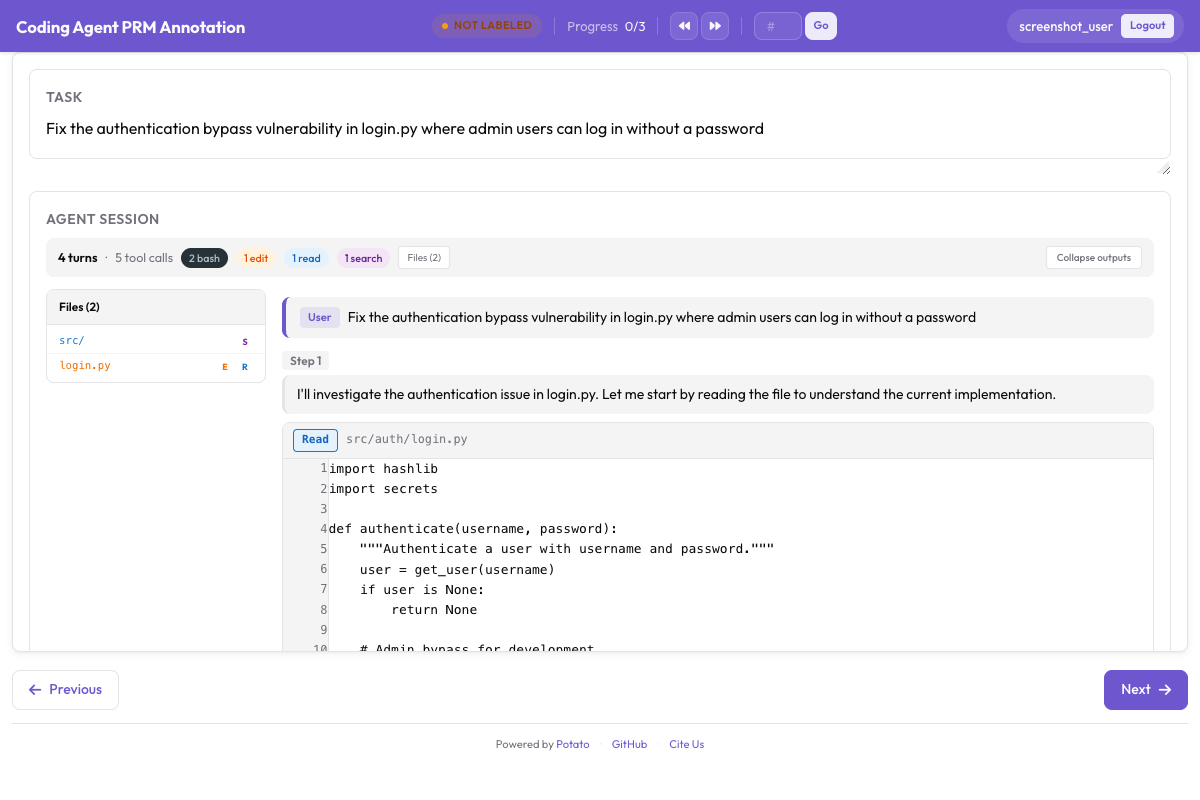 In first-error mode, click the first incorrect step and all subsequent steps are auto-marked
In first-error mode, click the first incorrect step and all subsequent steps are auto-marked
Per-Step Mode
In per-step mode, every step gets its own label. This produces richer data, since it captures cases where an agent partially recovers from an error, takes a harmless but unnecessary detour, or makes a step that's fine on its own but wrong in context.
annotation_schemes:
- annotation_type: process_reward
name: prm_per_step
mode: "per_step"
labels:
correct:
text: "Correct"
description: >
This step is logically sound, makes progress toward the goal,
and does not introduce bugs or unnecessary complexity.
keyboard_shortcut: "1"
color: "#22c55e"
partially_correct:
text: "Partially Correct"
description: >
This step is in the right direction but has flaws: incomplete
fix, unnecessary side effects, suboptimal approach, or missing
edge cases.
keyboard_shortcut: "2"
color: "#eab308"
incorrect:
text: "Incorrect"
description: >
This step is wrong, counterproductive, or introduces new bugs.
The agent should not have taken this action.
keyboard_shortcut: "3"
color: "#ef4444"
neutral:
text: "Neutral"
description: >
This step neither helps nor hurts. Includes reading files for
context or running diagnostic commands.
keyboard_shortcut: "4"
color: "#94a3b8"
require_all_steps: true
show_progress_bar: true
enable_keyboard_navigation: true
step_navigation:
next_step: "j"
previous_step: "k"
next_unlabeled: "n"Setting Up a PRM Annotation Project
Step 1: Prepare Your Trace Data
Your input data should be a JSONL file where each line is a JSON object containing the agent's trajectory. The key fields are id, issue_description, and structured_turns:
{
"id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"repo": "myorg/myproject",
"base_commit": "a1b2c3d",
"structured_turns": [
{
"step_idx": 0,
"type": "thinking",
"content": "I need to understand what parse_config does and where the TypeError occurs. Let me read the file first."
},
{
"step_idx": 1,
"type": "file_read",
"path": "src/config.py",
"content": "def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n return data['settings']",
"start_line": 1,
"end_line": 4
},
{
"step_idx": 2,
"type": "thinking",
"content": "The bug is on line 4. When the file is empty, json.load returns None, and None['settings'] raises TypeError. I should add a check."
},
{
"step_idx": 3,
"type": "file_edit",
"path": "src/config.py",
"diff": "--- a/src/config.py\n+++ b/src/config.py\n@@ -1,4 +1,6 @@\n def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n+ if data is None:\n+ return {}\n return data['settings']"
},
{
"step_idx": 4,
"type": "bash_command",
"command": "python -m pytest tests/test_config.py -v",
"output": "tests/test_config.py::test_parse_config_empty PASSED\ntests/test_config.py::test_parse_config_valid PASSED\n\n2 passed in 0.12s",
"exit_code": 0
}
]
}If you are converting from an existing agent format, use the trace converter tool:
# Convert Claude Code traces
potato convert-traces \
--format claude_code \
--input ./raw_traces/ \
--output ./data/traces.jsonl
# Convert SWE-Agent trajectories
potato convert-traces \
--format swe_agent \
--input ./swe_agent_output/ \
--output ./data/traces.jsonlPotato renders coding agent traces with proper diff highlighting:
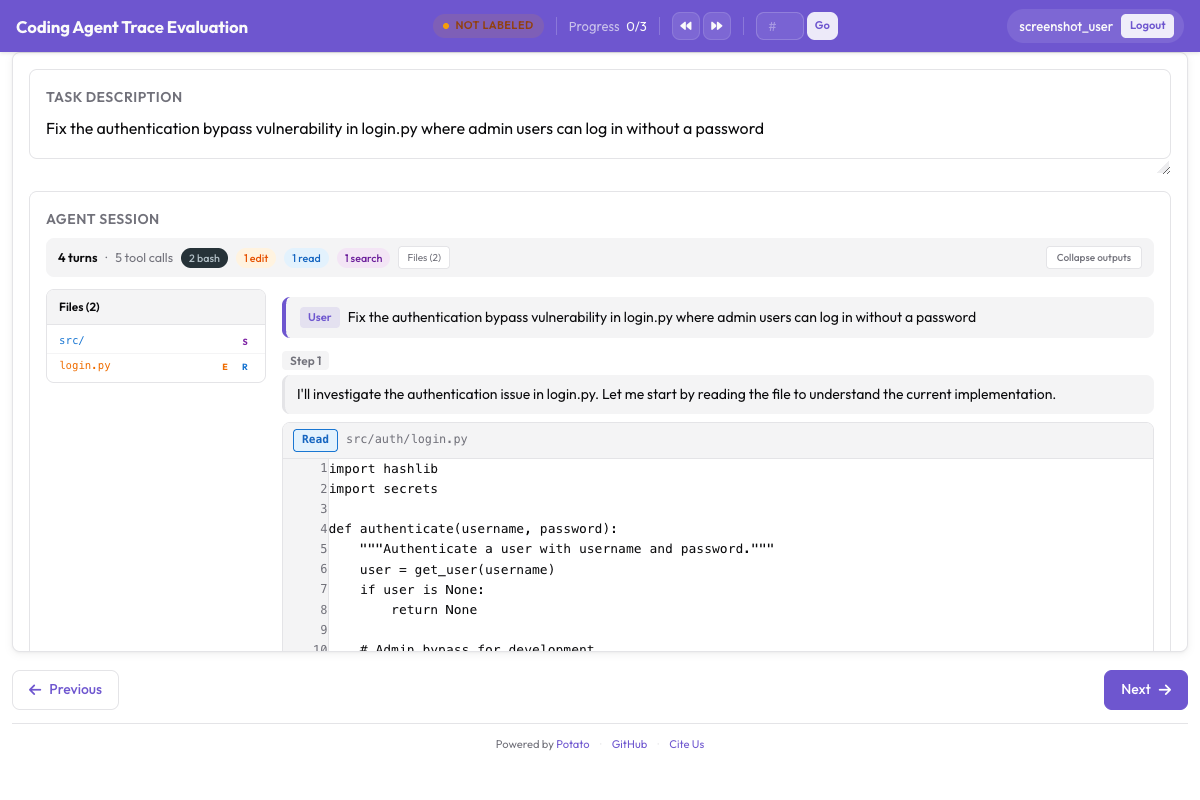 Code diffs, terminal output, and file reads are rendered with syntax highlighting
Code diffs, terminal output, and file reads are rendered with syntax highlighting
Step 2: Create Your Configuration
Here is a complete project configuration for PRM annotation using first-error mode:
# config.yaml
project_name: "PRM Data Collection - SWE-bench Traces"
port: 8000
data:
source: "local"
input_path: "./data/traces.jsonl"
data_format: "coding_trace"
coding_agent:
display:
diff_style: "unified"
context_lines: 3
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
position: "left"
collapsible:
auto_collapse_thinking: true
auto_collapse_long_output: true
long_output_threshold: 50
annotation_schemes:
- annotation_type: process_reward
name: step_reward
mode: "first_error"
labels:
correct: "Correct Step"
incorrect: "Incorrect Step"
allow_all_correct: true
allow_all_incorrect: true
description: >
Review the agent's trajectory step by step. Click the first
step where the agent makes an error. If the entire trajectory
is correct, click "All Correct."
highlight_clicked_step: true
confirmation_dialog: true
- annotation_type: radio
name: outcome
label: "Did the agent resolve the issue?"
options:
- value: "resolved"
text: "Fully Resolved"
- value: "partial"
text: "Partially Resolved"
- value: "not_resolved"
text: "Not Resolved"
- annotation_type: text_input
name: error_description
label: "If incorrect, briefly describe the error"
placeholder: "e.g., Agent edited the wrong file..."
required: false
show_if:
field: "step_reward"
condition: "has_error"
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 15
minimum_time_per_instance: 20
annotators:
- username: "reviewer1"
password: "pw_reviewer1"
- username: "reviewer2"
password: "pw_reviewer2"
- username: "reviewer3"
password: "pw_reviewer3"Step 3: Launch the Annotation Server
# Start the annotation server
potato start config.yaml -p 8000
# Or run in the background
nohup potato start config.yaml -p 8000 > potato.log 2>&1 &Navigate to http://localhost:8000, log in with one of the configured annotator accounts, and begin reviewing traces.
Step 4: Monitor Progress
While annotation is in progress, monitor progress and agreement:
# Check annotation progress
potato status config.yaml
# View inter-annotator agreement
potato agreement config.yaml --metric krippendorff_alphaExporting to Training Formats
Once annotation is complete, export the data in the format your training pipeline expects.
PRM Format for Reward Model Training
The PRM export format produces one JSON object per trace with step-level labels:
potato export \
--format prm \
--project ./output/ \
--output ./training_data/prm_labels.jsonlThe output looks like this:
{
"trace_id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"total_steps": 5,
"first_error_step": null,
"all_correct": true,
"steps": [
{"step_idx": 0, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 1, "type": "file_read", "label": "correct", "reward": 1.0},
{"step_idx": 2, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 3, "type": "file_edit", "label": "correct", "reward": 1.0},
{"step_idx": 4, "type": "bash_command", "label": "correct", "reward": 1.0}
]
}DPO/RLHF Preference Pairs
When you have multiple traces for the same issue (e.g., from different agents or different runs), Potato can generate preference pairs based on PRM labels:
potato export \
--format preference_pairs \
--project ./output/ \
--output ./training_data/preferences.jsonl \
--pair_by "issue_id"The preference pair export compares traces that attempted the same task and selects the better one based on step-level labels:
{
"prompt": "Fix the TypeError in parse_config() when config file is empty",
"chosen_trace_id": "trace_001",
"rejected_trace_id": "trace_002",
"chosen_first_error": null,
"rejected_first_error": 3,
"chosen_steps": 5,
"rejected_steps": 7,
"margin": 0.8
}SWE-bench Compatible Results
Export in SWE-bench format for benchmarking:
potato export \
--format swe_bench \
--project ./output/ \
--output ./training_data/swe_bench_results.jsonAnalysis Examples
After collecting annotations, use these Python snippets to analyze the data and identify patterns.
Step-Level Accuracy by Step Type
import json
from collections import defaultdict
# Load PRM annotations
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Compute accuracy by step type
type_stats = defaultdict(lambda: {"correct": 0, "total": 0})
for trace in traces:
for step in trace["steps"]:
step_type = step["type"]
type_stats[step_type]["total"] += 1
if step["label"] == "correct":
type_stats[step_type]["correct"] += 1
print("Step-Level Accuracy by Type:")
print("-" * 45)
for step_type, stats in sorted(type_stats.items()):
acc = stats["correct"] / stats["total"] * 100
print(f" {step_type:<20} {acc:5.1f}% ({stats['correct']}/{stats['total']})")Finding Common Failure Points
import json
from collections import Counter
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Analyze where errors first occur
error_positions = []
error_types_at_first_error = Counter()
for trace in traces:
if trace["first_error_step"] is not None:
pos = trace["first_error_step"]
total = trace["total_steps"]
# Normalize position to 0-1 range
error_positions.append(pos / total)
# Track what type of step caused the first error
error_step = trace["steps"][pos]
error_types_at_first_error[error_step["type"]] += 1
if error_positions:
avg_pos = sum(error_positions) / len(error_positions)
print(f"Average first-error position: {avg_pos:.2f} (0=start, 1=end)")
print(f"Traces with errors: {len(error_positions)}/{len(traces)}")
print()
print("Most common step types at first error:")
for step_type, count in error_types_at_first_error.most_common(5):
print(f" {step_type}: {count}")Computing Inter-Annotator Agreement on PRM Labels
import json
import numpy as np
from sklearn.metrics import cohen_kappa_score
def load_annotations(annotator_file):
"""Load annotations from a single annotator's output file."""
with open(annotator_file) as f:
data = {item["trace_id"]: item for item in
(json.loads(line) for line in f)}
return data
ann1 = load_annotations("output/reviewer1/annotations.jsonl")
ann2 = load_annotations("output/reviewer2/annotations.jsonl")
# Find overlapping traces
overlap_ids = set(ann1.keys()) & set(ann2.keys())
print(f"Overlapping traces: {len(overlap_ids)}")
# Compare first-error step labels
labels1 = []
labels2 = []
for trace_id in overlap_ids:
fe1 = ann1[trace_id].get("first_error_step", -1)
fe2 = ann2[trace_id].get("first_error_step", -1)
# Bin into: all_correct, early_error (first half), late_error (second half)
total = ann1[trace_id]["total_steps"]
for fe, labels in [(fe1, labels1), (fe2, labels2)]:
if fe is None or fe == -1:
labels.append("all_correct")
elif fe < total / 2:
labels.append("early_error")
else:
labels.append("late_error")
kappa = cohen_kappa_score(labels1, labels2)
print(f"Cohen's kappa (binned first-error): {kappa:.3f}")Tips for Efficient PRM Data Collection
Use first-error mode for speed. If you're training a PRM to guide search (MCTS, best-of-N sampling), first-error mode gives you enough signal at 2-3x the annotation speed of per-step mode. Most agents fail in a cascade anyway: one mistake leads to a chain of bad steps.
Use per-step mode when you need the detail. If you care about partial recovery, harmless detours, or you're building a step-level reward model with more than two labels, per-step mode earns its extra time.
Combine PRM with pairwise comparison. Label traces individually with PRM, then run a pairwise comparison on traces that attempted the same issue. One annotation pass gives you both step-level rewards and preference pairs.
Start with experienced annotators. PRM annotation means reading code, diffs, and terminal output. Begin with a small group of experienced developers, measure agreement, calibrate against examples, then scale up.
Set a minimum time per instance. Traces get complicated. A 30-second floor keeps annotators from racing through without actually reading the changes. Tune it to your average trace length.
Provide calibration examples. Before production annotation, have everyone label the same 10-20 traces and talk through where they disagreed. It makes a big difference to consistency.