Dá para confiar no seu juiz LLM? Calibrar LLM-as-Judge frente a humanos
Usar um LLM para avaliar as saídas de um modelo é fácil. Saber se vale a pena acreditar nele é a parte difícil. Um passeio pela calibração humana às cegas do Potato 2.6: votação com k amostras, kappa de Cohen e de Fleiss, e o erro de calibração esperado.
Usar um modelo de linguagem grande para avaliar as saídas de outros modelos virou a jogada padrão na avaliação. Você escreve uma rubrica, pede ao GPT-4o ou ao Claude que pontue mil respostas e lê um número de acurácia. É rápido, é barato e escala muito além de qualquer coisa que uma equipe humana consiga rotular à mão.
Mas também pressupõe, em silêncio, justamente aquilo que você mais precisa verificar: que o juiz concorda com as pessoas. Um LLM como juiz que erra com confiança produz um placar de aparência limpa, construído sobre areia. Antes de confiar nos veredictos de um juiz, você precisa medir o quanto eles acompanham o julgamento humano. Esse passo de medição é a calibração, e o Potato 2.6 adiciona um fluxo de trabalho para isso.
Este post aborda Judge Calibration (calibração do juiz): como ela amostra os modelos, como mantém honesta a passagem humana e o que o relatório realmente diz a você. A documentação de referência tem a lista completa de opções.
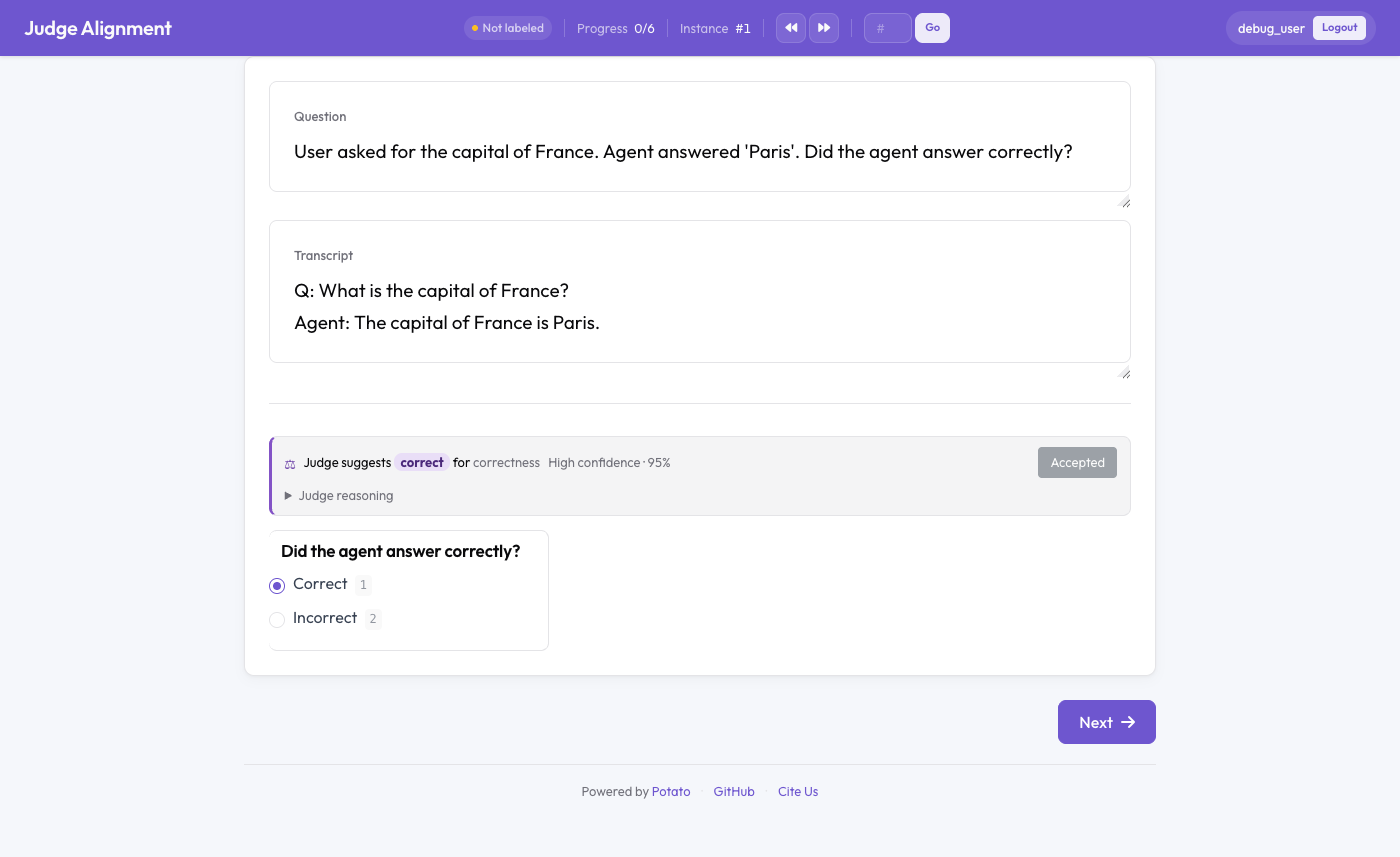 Calibração do juiz em linha no Potato
Calibração do juiz em linha no Potato
O formato do problema
Um juiz pode falhar de duas formas diferentes, e você quer capturar as duas.
A primeira é a discordância: o juiz chama de "correto" o que uma pessoa cuidadosa chamaria de "errado". É isso que as métricas de acurácia e de concordância medem.
A segunda é a confiança equivocada: o juiz diz estar 95% seguro e acerta 60% das vezes. Um juiz pode ter uma acurácia razoável e ainda assim estar muito mal calibrado, o que importa no momento em que você começa a usar a confiança dele para encaminhar trabalho ou definir limiares. É isso que o erro de calibração mede.
A passagem de calibração do Potato foi feita para trazer à tona os dois de uma vez.
Como funciona
O fluxo de trabalho roda como uma breve máquina de estados:
SETUP → GENERATING → HUMAN_CALIBRATION → REPORT → COMPLETED
Geração (Generating). Cada modelo é consultado k vezes por item. O rótulo modal entre essas k amostras é a previsão do modelo, e a fração de amostras que concordam com ela é a sua confiança. Amostrar k vezes em vez de uma só é o que te dá um sinal de confiança empírico, em vez de um número que o modelo inventou sobre si mesmo. Esses resultados vão para um armazenamento dedicado e nunca são gravados nos dados de anotação.
Calibração humana (Human calibration). O Potato extrai uma amostra aleatória ou estratificada dos itens e a encaminha a uma ou mais pessoas, que os rotulam pela interface de anotação normal, sem nunca ver as respostas do modelo.
Relatório (Report). As métricas são calculadas sobre a sobreposição entre o que os modelos rotularam e o que as pessoas rotularam, e então gravadas em disco.
A cegueira aqui é a parte importante. Como os rótulos do modelo ficam em um armazenamento separado e nunca são injetados na interface, a pessoa não pode ser ancorada por eles, nem por acidente. A cegueira é estrutural, não uma questão de pedir aos anotadores que desviem o olhar.
 Como o Potato calibra um juiz frente a rótulos humanos às cegas
Como o Potato calibra um juiz frente a rótulos humanos às cegas
Configuração
Uma calibração de juiz é um único bloco de configuração. Você escreve o prompt do juiz, lista os modelos e define quantas vezes amostrar cada um:
judge_calibration:
enabled: true
prompt: | # supports {text}, {labels}, {description}
You are an impartial expert annotator. Classify the sentiment as exactly
one of: positive, negative, neutral.
models:
- endpoint_type: openai # openai | anthropic | ollama | vllm | gemini | ...
model: gpt-4o-mini
api_key: ${OPENAI_API_KEY}
temperature: 0.7 # must be > 0 so the k samples vary
- endpoint_type: ollama
model: llama3.1:8b
base_url: http://localhost:11434
temperature: 0.7
k_samples: 5 # samples per model per item
max_items: 1000 # cap on items the LLMs label (null = all)
sampling:
strategy: stratified # random | stratified | all
sample_size: 200 # how many items humans blind-label
seed: 42
human:
num_raters: 1 # 1 = solo researcher; N adds human-human IAA
gold: single # single | majority
schemas: [sentiment]
output:
dir: judge_calibration_outputWarning: Defina
temperature > 0. Comk_samples > 1e temperatura 0, as amostras são idênticas, a confiança fica fixada em 1.0 e o relatório de calibração não significa nada. O Potato emite um aviso na inicialização quando vê essa combinação.
Você pode listar mais de um modelo e calibrá-los lado a lado, que é a forma natural de escolher entre um juiz local barato e um hospedado caro.
Experimentar sem chave de API
O exemplo incluído usa um modelo Ollama local, então você pode rodar todo o ciclo offline. Inicie o Ollama, baixe o modelo e lance:
ollama pull llama3.2:3b
python potato/flask_server.py start examples/ai-assisted/judge-calibration/config.yaml -p 8000 --debugAbra http://localhost:8000/judge_calibration/admin para configurar e executar, rotule às cegas a amostra em /annotate, depois gere o relatório e leia-o em /judge_calibration/report.
O que o relatório diz a você
O relatório foi feito para responder "devo confiar neste juiz?" com números que você pode colocar em uma seção de métodos:
- Acurácia, precisão, revocação (recall) e F1 de cada modelo frente ao rótulo de ouro humano.
- κ de Cohen desdobrado em pares humano↔modelo, modelo↔modelo e humano↔humano, para que você veja se o juiz concorda com as pessoas tanto quanto as pessoas concordam entre si.
- κ de Fleiss e α de Krippendorff sobre todos os avaliadores.
- Erro de calibração esperado (ECE), bins de confiabilidade e um escore de Brier: a resposta ao modo de falha da confiança equivocada.
- Uma matriz de confusão por modelo, que costuma contar a história verdadeira: um juiz que vai bem nas classes fáceis e desmorona em uma distinção difícil.
Tudo é calculado sobre a sobreposição: os itens rotulados tanto pelos modelos quanto pelas pessoas, restritos à amostra de calibração. A saída fica sob output.dir como llm_labels.jsonl, report.json e um report.html legível.
O que ela trata
A calibração é totalmente suportada nos esquemas categóricos que a maioria dos juízes usa, e alcança tipos mais difíceis:
| Tipo | Status | Métricas |
|---|---|---|
radio / select | Suportado | acurácia, P/R/F1, κ de Cohen/Fleiss, α de Krippendorff, ECE, confusão |
likert | Suportado | o acima mais MAE e α de Krippendorff ordinal |
multiselect | Suportado | P/R/F1 por rótulo, Jaccard médio, acurácia de correspondência exata, calibração |
span | Experimental | P/R/F1 emparelhados por IoU, IoU médio, span-F1, calibração no nível de span |
A calibração de spans agrupa os spans de deslocamento de caractere do juiz ao longo das k amostras e os emparelha ao ouro por interseção sobre união (intersection-over-union); trate seus números como indicativos, e não exatos.
Calibração versus alinhamento
O Potato traz um segundo fluxo de trabalho, aparentado, fácil de confundir com este. Judge Alignment (alinhamento do juiz) calibra um único juiz frente a um conjunto de ouro humano existente, mostra seu veredicto em linha durante a anotação e foi pensado para iterar sobre uma rubrica até a concordância subir.
A regra prática: recorra à calibração quando estiver avaliando juízes candidatos e quiser um número de confiança empírico e às cegas; recorra ao alinhamento quando já tiver se decidido por um juiz e estiver ajustando sua rubrica frente a um conjunto de ouro fixo. Os dois são tratados juntos em Fechar o ciclo (Closing the Loop).
Os juízes LLM não vão desaparecer; há muito a avaliar e gente de menos para fazê-lo à mão. O propósito da calibração não é substituir o juiz por pessoas, mas saber, com um número, exatamente até onde se pode confiar no juiz antes que uma pessoa precise olhar.
A documentação de Judge Calibration cobre cada opção, e o guia de concordância entre anotadores explica em profundidade as métricas kappa e alpha.