Da avaliação aos dados de treino: edição de trajetórias para SFT e DPO
A maioria das avaliações de agentes para numa pontuação. O esquema trajectory_edit do Potato 2.6 permite que os anotadores reescrevam um passo errado em vez de o classificarem, e exporta cada correção como alvos de fine-tuning supervisionado e pares de preferência para DPO.
A avaliação de um agente costuma terminar com um número. Um anotador lê uma trajetória, decide que o terceiro passo estava errado e regista uma pontuação baixa ou marca um tipo de erro. Esse número é útil para medir com que frequência o agente falha. É muito menos útil para corrigir o agente, porque "o terceiro passo estava errado" não diz ao modelo qual deveria ter sido o terceiro passo.
A próxima versão Potato 2.6 acrescenta um esquema que pede a resposta em vez da nota. Com trajectory_edit, os anotadores reescrevem os passos de um agent trace (rasto de agente): corrigem um passo de raciocínio mal feito, reparam uma tool call (chamada de ferramenta) com um erro de digitação ou reforçam uma resposta final fraca, e o Potato mantém a trajetória corrigida ao lado da original. O exportador trajectory_correction transforma então cada par (original, corrected) em dados de treino: alvos de fine-tuning supervisionado e pares de preferência de otimização direta de preferências.
É dessa mudança que trata este artigo. Transforma uma ferramenta de avaliação numa ferramenta de produção de dados de treino e muda o que o tempo de um anotador humano produz: não um rótulo, mas um sinal de aprendizagem.
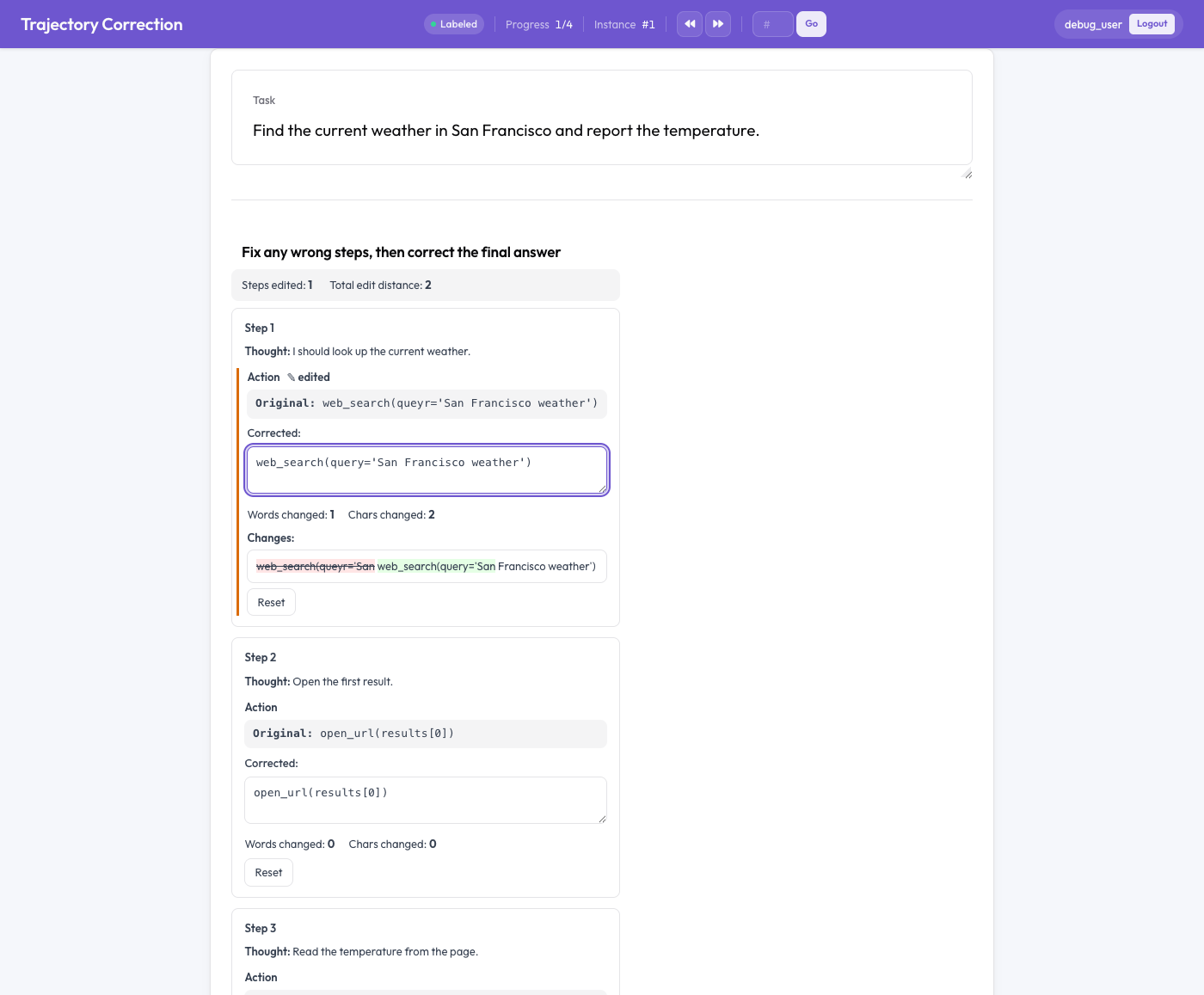 O editor de correção de trajetórias
O editor de correção de trajetórias
Editar em vez de pontuar
Cada passo do agente é apresentado como um cartão com duas metades: o texto original, só de leitura, e uma caixa corrigida editável pré-preenchida com o original. O anotador edita a caixa corrigida diretamente. À medida que digita, acontecem três coisas:
- um diff ao vivo ao nível da palavra realça as inserções a verde e as eliminações a vermelho rasurado,
- contam-se as palavras e os caracteres alterados, e
- surge uma marca "edited" (editado) em qualquer campo que tenha mudado.
Um botão "Reset" restaura o original de um campo se o anotador mudar de ideias. O essencial: nada é obrigatório. Um anotador que lê um rasto e o considera correto simplesmente o deixa como está, e um rasto não editado não produz nenhum par de treino. O sinal vem apenas de correções reais.
Configuração
O esquema aponta para a lista de passos nos teus dados e indica quais campos são editáveis:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerPor predefinição, apenas a action de cada passo é editável. Adiciona thought a editable_fields quando quiseres que os anotadores reparem o raciocínio do agente além das suas ações, e define require_reason_on_edit: true quando quiseres anexar uma justificação escrita a cada alteração, o que ajuda quando as próprias correções vão ser revistas.
O formato dos dados é exatamente o que os teus rastos já têm. O esquema lê os passos do campo indicado por steps_key; cada passo é um objeto cujos campos podem ser editados:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}O erro de digitação em queyr é exatamente o tipo de coisa que um anotador corrige na caixa corrigida, produzindo uma correção de um único token com a qual o modelo pode aprender.
Executa o exemplo incluído a partir da raiz do repositório:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000Das correções aos ficheiros de treino
O exportador trajectory_correction escreve três ficheiros, cada um para um uso a jusante diferente:
trajectory_corrections.jsonguarda o registo completo: ooriginal_trace, ocorrected_tracereconstruído e oseditspor campo com distâncias de edição e motivos. É o teu rasto de auditoria.trajectory_sft.jsonltem uma linha por rasto editado,{"prompt": <task>, "completion": <corrected_trace>}. A trajetória corrigida torna-se o alvo que um modelo é treinado, por fine-tuning, a reproduzir.trajectory_dpo.jsonltem uma linha por rasto editado,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. A edição do humano define a preferência: a corrigida sobre a original.
 Como as edições se tornam dados de treino SFT e DPO
Como as edições se tornam dados de treino SFT e DPO
O ficheiro DPO é a parte que vem de graça. Numa pipeline normal de dados de preferência, é preciso gerar ou recolher uma resposta pior para emparelhar com a melhor. Aqui a resposta pior já existe (é a trajetória original que o agente produziu) e a edição do humano é a prova de que a versão corrigida é a preferida. Uma única anotação rende tanto um alvo SFT como um par DPO.
O que é ignorado, e por que isso importa
Os rastos não editados são contados, mas excluídos dos ficheiros SFT e DPO. Treinar numa trajetória inalterada não ensina nada ao modelo e, pior, inundaria um conjunto de dados de preferência com pares chosen == rejected que acrescentam ruído. A contagem dos ignorados continua a aparecer nas estatísticas de exportação, por isso podes ver que parte do lote já estava correta, em si um sinal útil sobre a qualidade do agente. Com vários anotadores, cada anotador que editou um dado rasto rende um registo SFT/DPO, de modo que todas as correções independentes contribuem.
Algumas arestas vivas
- O diff é ao nível da palavra. Para tool calls (chamadas de ferramenta) semelhantes a código e sem espaços, um único token pode aparecer como totalmente alterado mesmo numa correção de um só caractere. O contador de distância de caracteres é o sinal preciso nesses casos; confia nele em vez do diff visual para chamadas de ferramenta densas.
- Editar combina naturalmente com pontuar. Se também quiseres rótulos de correção por passo ou uma taxonomia de erros no mesmo rasto, corre um esquema de pontuação ao nível do passo a par do editor, para que uma única passagem produza tanto o diagnóstico como a correção.
Por que isto importa
O ciclo de ajuste de agentes sempre teve um estrangulamento no passo "o que deveria ter feito". As pontuações dizem-te onde um modelo falha; não produzem o comportamento corrigido para treinar, por isso as equipas acabam por escrever correções sintéticas ou pagar uma segunda ronda de rotulagem. A edição de trajetórias condensa isso na própria avaliação. A mesma pessoa que teria pontuado o rasto repara-o, e a reparação é o dado de treino.
A edição de trajetórias chega no Potato 2.6. Consulta a documentação de edição de trajetórias para a lista completa de opções, a visualização eval_trace para ler rastos rapidamente antes de editar, e a referência de formatos de exportação para os detalhes do exportador.