Fechando o ciclo: encaminhar de volta às pessoas os erros do agente e as discordâncias do juiz
O tempo de revisão humana é o recurso mais escasso na avaliação de agentes. O Potato 2.6 combina uma fila de triagem baseada em sinais com o alinhamento juiz-humano, para que os piores rastros cheguem primeiro às pessoas e seu juiz LLM continue melhorando.
Assim que você avalia agentes em qualquer escala, a restrição deixa de ser "conseguimos rotular isto" e passa a ser "em quem gastamos a atenção, e em quê". Você tem milhares de rastros de produção e um punhado de revisores. Um juiz LLM pode pré-triar tudo, mas é imperfeito, e os casos em que ele erra são exatamente os que merecem o tempo de uma pessoa.
Dois recursos do Potato 2.6 trabalham juntos para administrar essa escassez. Uma fila de triagem baseada em sinais decide o que as pessoas veem primeiro. O alinhamento juiz-humano mede o quanto você pode se apoiar no juiz e o aprimora. Execute-os juntos e você obtém um ciclo de avaliação ativo: o juiz dá conta do volume fácil, os casos suspeitos furam a fila até as pessoas e as discordâncias retroalimentam um juiz melhor.
Este post cobre as duas metades e como elas se conectam.
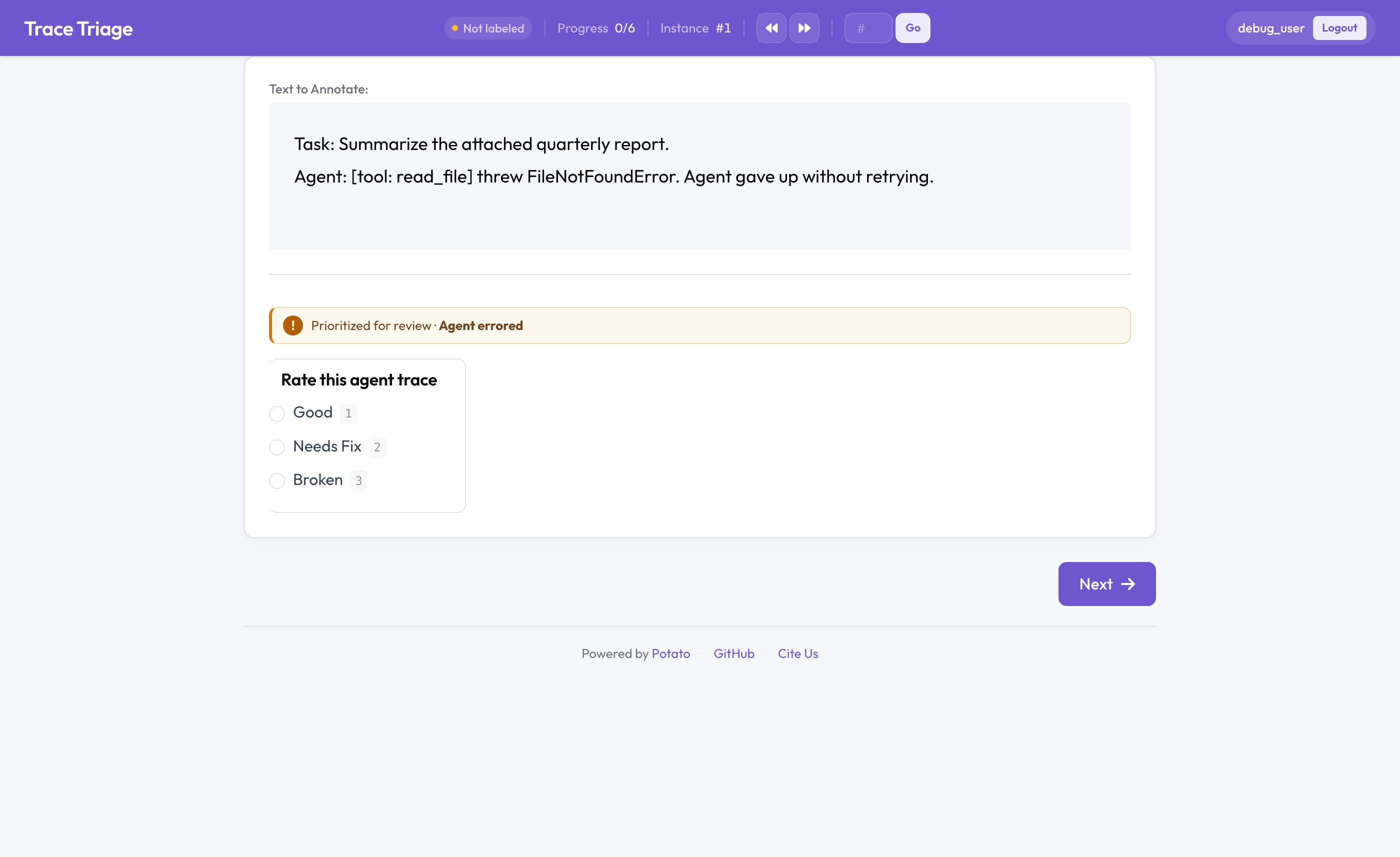 O selo da fila de triagem no Potato
O selo da fila de triagem no Potato
A metade da triagem: o pior primeiro, não o primeiro a entrar primeiro a sair
Por padrão, uma fila de anotação é FIFO: os itens são servidos na ordem em que foram carregados. Essa é a ordem errada quando o tempo de revisão é escasso. Um rastro limpo e um rastro em que o agente lançou um erro merecem quantidades de atenção humana bem diferentes, e o FIFO os trata da mesma forma.
A fila de triagem reordena a fila por um sinal de qualidade por item. O sinal pode ser um erro do agente, um polegar para baixo em produção, uma pontuação automática baixa ou qualquer campo dos seus dados:
triage:
enabled: true
order: desc # high priority first (default)
show_badge: true # banner during annotation explaining the priority
rules: # evaluated in order; highest matching priority wins
- name: "Agent errored"
priority: 100
when:
field: status
equals: error
- name: "Negative feedback"
priority: 80
when:
field: feedback
in: [thumbs_down, negative]
- name: "Low quality score"
priority: 60
when:
field: score
lt: 0.5
assignment_strategy: priorityAs regras são avaliadas de cima para baixo e a prioridade correspondente mais alta vence, então um rastro com erro que também tem feedback negativo ainda assim para em 100. Se você omitir rules por completo, o Potato recorre a um conjunto padrão sensato (status de erro em 100, feedback negativo em 80, pontuação abaixo de 0.5 em 60), de modo que o comportamento pronto para uso é razoável antes de qualquer ajuste.
Os operadores de condição cobrem as comparações de que você realmente precisa:
| Operator | Significado |
|---|---|
equals | correspondência exata (strings não diferenciam maiúsculas/minúsculas) |
in | o valor é um de uma lista |
contains | a lista contém, ou correspondência de substring |
lt / lte / gt / gte | comparação numérica |
exists | o campo está presente ou ausente |
Quando o sinal já é um número, você pode lê-lo direto do campo em vez de escrever regras:
triage:
enabled: true
signal_field: quality_score
invert_signal: true # lower score => higher priorityTambém funciona com tráfego ao vivo
A pontuação de prioridade é calculada uma única vez quando um item é carregado ou ingerido, e então armazenada no item, de modo que a atribuição continua barata. Esse mesmo design faz com que a ingestão em tempo de execução simplesmente funcione: um rastro empurrado no meio da sessão pelo endpoint webhook ou um poller do Langfuse é pontuado ao chegar e se encaixa na ordem de prioridade. Um rastro de baixa pontuação ou com erro que chega às 14h passa à frente dos limpos que ainda esperam desde a manhã. Definir assignment_strategy: priority é o que faz a fila servir de fato nessa ordem; show_badge é independente, então o banner de "por que isto foi sinalizado" aparece mesmo que você mantenha outra estratégia.
A metade do alinhamento: o quanto confiar no juiz
A triagem decide o que as pessoas veem. O alinhamento decide quanto do restante você pode entregar ao juiz sem supervisão, e aperta o juiz ao longo do tempo.
O Judge Alignment executa um juiz LLM configurável sobre instâncias que seus anotadores já rotularam, e então reporta o κ de Cohen (kappa de Cohen, uma medida de concordância), uma matriz de confusão e uma lista de discordâncias frente ao gold humano. A prática padrão (alinhar um juiz a cerca de 100 a 200 rótulos gold, inspecionar onde ele diverge, reescrever a rubric e reexecutar) é o ciclo em torno do qual isto foi construído.
ai_support:
enabled: true
endpoint_type: "ollama"
ai_config:
model: "llama3.2"
temperature: 0.0
judge_alignment:
enabled: true
schemas:
correctness:
rubric: >
Label 'correct' only if the agent's answer is factually right and fully
satisfies the request; otherwise 'incorrect'.
inline:
enabled: true # show the judge verdict beside the human label
schemas: [correctness]Você executa o juiz pela API de administração, e as previsões são armazenadas em cache por versão de prompt, de modo que as reexecuções saem baratas:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" \
-H "Content-Type: application/json" \
-d '{"max_per_schema": 200}'Quando quiser calibrar, passe uma rubric editada. Isso cria uma nova versão de prompt, de modo que você pode comparar κ entre as rodadas e ver de fato se sua reescrita ajudou:
curl -X POST localhost:8000/admin/api/judge-alignment/run \
-H "X-API-Key: <admin-key>" -H "Content-Type: application/json" \
-d '{"rubrics": {"correctness": "Stricter rubric text..."}}'O relatório, disponível como JSON ou como página renderizada em /admin/judge-alignment, mostra κ com uma interpretação Landis–Koch, a matriz de confusão, uma tabela de discordâncias com o raciocínio do juiz e um histórico de versões de prompt, de modo que o progresso da calibração fique visível entre as rodadas.
O modo inline coloca isso diante do anotador
Com inline.enabled, cada página de anotação mostra o veredicto em cache do juiz ao lado do rótulo humano (sua escolha, confiança e um raciocínio expansível) junto a um κ corrente para a tarefa. "Aceitar" preenche a escolha correspondente. Cada salvamento humano registra uma comparação humano↔juiz que alimenta a concordância corrente, então o κ rumo ao qual você está calibrando se atualiza à medida que as pessoas trabalham.
Juntando os dois
Os recursos foram desenhados para se compor em um único ciclo:
 O ciclo de avaliação ativo: triagem, revisão humana, alinhamento do juiz, refinamento da rubric
O ciclo de avaliação ativo: triagem, revisão humana, alinhamento do juiz, refinamento da rubric
- A triagem empurra os rastros com erro e de baixa confiança para a frente da fila humana.
- As pessoas revisam esses itens de alto valor, produzindo rótulos gold frescos exatamente onde o sistema está menos seguro.
- O alinhamento pontua o juiz frente a esse gold, e a lista de discordâncias mostra com precisão onde o juiz e as pessoas se separam.
- Você refina a rubric, reexecuta e observa κ se mover; depois deixa o juiz mais bem calibrado absorver mais do volume fácil, para que o tempo humano continue fluindo para os casos difíceis.
Cada volta do ciclo gasta a atenção humana onde ela vale mais e a converte em um juiz no qual você pode confiar um pouco mais. É justamente esse o ponto: não remover as pessoas da avaliação de agentes, mas mirá-las.
Ambos os recursos vêm no Potato 2.6. Consulte os documentos da fila de triagem e os documentos do alinhamento do juiz para a referência completa, e a exibição eval_trace para ler rapidamente os rastros priorizados.