मूल्यांकन से प्रशिक्षण डेटा तक: SFT और DPO के लिए ट्रैजेक्टरी संपादन
अधिकांश एजेंट मूल्यांकन एक स्कोर पर रुक जाते हैं। Potato 2.6 का trajectory_edit स्कीमा एनोटेटर को किसी गलत चरण को रेट करने के बजाय उसे फिर से लिखने देता है, और हर सुधार को सुपरवाइज़्ड फाइन-ट्यूनिंग लक्ष्यों और DPO वरीयता जोड़ों के रूप में निर्यात करता है।
एजेंट मूल्यांकन आमतौर पर एक संख्या के साथ समाप्त होता है। एक एनोटेटर किसी ट्रैजेक्टरी को पढ़ता है, तय करता है कि तीसरा चरण गलत था, और एक कम स्कोर दर्ज करता है या किसी त्रुटि प्रकार को टैग कर देता है। वह संख्या यह मापने के लिए उपयोगी है कि एजेंट कितनी बार विफल होता है। पर एजेंट को ठीक करने के लिए वह कहीं कम उपयोगी है, क्योंकि "तीसरा चरण गलत था" यह मॉडल को नहीं बताता कि तीसरा चरण क्या होना चाहिए था।
आने वाला Potato 2.6 रिलीज़ एक ऐसा स्कीमा जोड़ता है जो ग्रेड के बजाय उत्तर माँगता है। trajectory_edit के साथ, एनोटेटर एक agent trace (एजेंट ट्रैजेक्टरी) के चरणों को फिर से लिखते हैं — किसी बिगड़े हुए तर्क चरण को सुधारते हैं, किसी टाइपो वाली tool call (टूल कॉल) की मरम्मत करते हैं, या किसी कमज़ोर अंतिम उत्तर को मज़बूत करते हैं — और Potato सुधारी गई ट्रैजेक्टरी को मूल के साथ-साथ रखता है। इसके बाद trajectory_correction निर्यातक प्रत्येक (original, corrected) जोड़े को प्रशिक्षण डेटा में बदल देता है: सुपरवाइज़्ड फाइन-ट्यूनिंग लक्ष्य और डायरेक्ट प्रेफरेंस ऑप्टिमाइज़ेशन वरीयता जोड़े।
यह पोस्ट इसी बदलाव के बारे में है। यह एक मूल्यांकन उपकरण को प्रशिक्षण-डेटा उत्पादन उपकरण में बदल देता है, और यह भी बदल देता है कि एक मानव एनोटेटर का समय क्या उत्पन्न करता है: एक लेबल नहीं, बल्कि एक सीखने का संकेत।
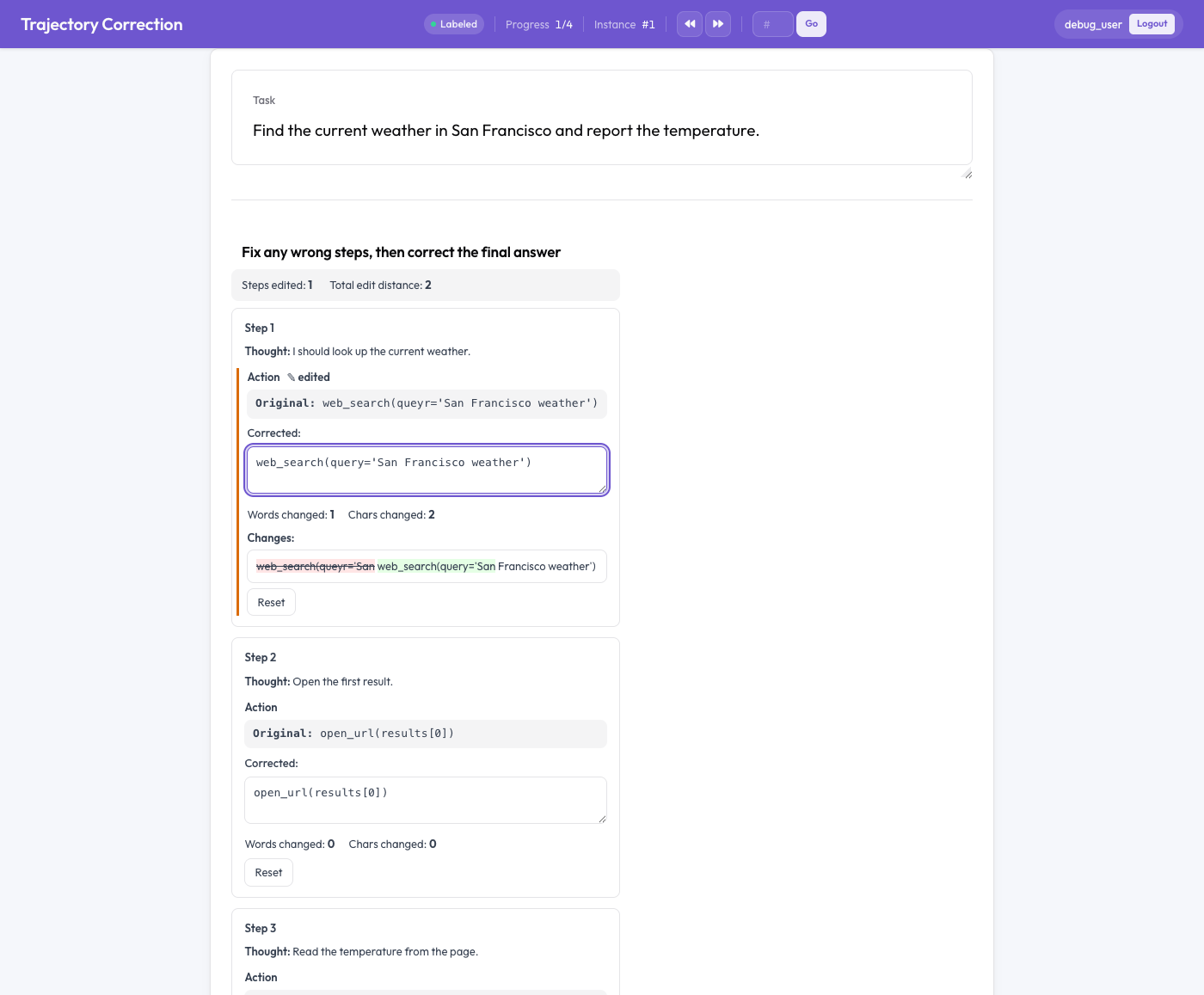 ट्रैजेक्टरी सुधार संपादक
ट्रैजेक्टरी सुधार संपादक
स्कोर देने के बजाय संपादन करना
प्रत्येक एजेंट चरण एक कार्ड के रूप में दो हिस्सों में दिखता है: मूल टेक्स्ट, केवल-पठनीय, और एक संपादन-योग्य सुधारित बॉक्स जिसमें मूल पहले से भरा होता है। एनोटेटर सीधे सुधारित बॉक्स को संपादित करता है। जैसे-जैसे वह टाइप करता है, तीन चीज़ें होती हैं:
- एक लाइव शब्द-स्तरीय डिफ़ जोड़ों को हरे रंग में और हटाई गई चीज़ों को लाल काट (स्ट्राइकथ्रू) में हाइलाइट करता है,
- बदले गए शब्दों और अक्षरों की गिनती होती है, और
- जो भी फ़ील्ड बदला हो उस पर एक "edited" (संपादित) फ़्लैग दिखाई देता है।
यदि एनोटेटर अपना मन बदल ले तो एक "Reset" बटन किसी फ़ील्ड के मूल को बहाल कर देता है। महत्वपूर्ण बात यह है कि कुछ भी अनिवार्य नहीं है। जो एनोटेटर किसी ट्रेस को पढ़कर उसे सही पाता है, वह उसे बस वैसे ही छोड़ देता है, और एक असंपादित ट्रेस कोई प्रशिक्षण जोड़ा उत्पन्न नहीं करता। संकेत केवल वास्तविक सुधारों से आता है।
कॉन्फ़िगरेशन
स्कीमा आपके डेटा में चरण सूची की ओर इंगित करता है और बताता है कि कौन-से फ़ील्ड संपादन-योग्य हैं:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerडिफ़ॉल्ट रूप से प्रत्येक चरण की केवल action संपादन-योग्य होती है। जब आप चाहते हैं कि एनोटेटर एजेंट की क्रियाओं के साथ-साथ उसके तर्क की भी मरम्मत करें, तो thought को editable_fields में जोड़ें, और जब आप चाहते हैं कि हर बदलाव के साथ एक लिखित औचित्य संलग्न हो, तो require_reason_on_edit: true सेट करें — यह तब मददगार होता है जब सुधारों की स्वयं समीक्षा की जानी हो।
डेटा प्रारूप वही है जैसा आपकी ट्रेस पहले से दिखती हैं। स्कीमा steps_key द्वारा नामित फ़ील्ड से चरण पढ़ता है; प्रत्येक चरण एक ऑब्जेक्ट है जिसके फ़ील्ड संपादित किए जा सकते हैं:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}queyr में टाइपो ठीक उसी तरह की चीज़ है जिसे एनोटेटर सुधारित बॉक्स में ठीक करता है, जिससे एक ही टोकन का सुधार उत्पन्न होता है जिससे मॉडल सीख सकता है।
रिपॉज़िटरी की रूट से साथ दिए गए उदाहरण को चलाएँ:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000सुधारों से प्रशिक्षण फ़ाइलों तक
trajectory_correction निर्यातक तीन फ़ाइलें लिखता है, हर एक अलग डाउनस्ट्रीम उपयोग के लिए:
trajectory_corrections.jsonपूरा रिकॉर्ड रखता है:original_trace, पुनर्निर्मितcorrected_trace, और संपादन दूरियों एवं कारणों के साथ प्रति-फ़ील्डedits। यह आपका ऑडिट ट्रेल है।trajectory_sft.jsonlमें प्रत्येक संपादित ट्रेस के लिए एक पंक्ति होती है,{"prompt": <task>, "completion": <corrected_trace>}। सुधारी गई ट्रैजेक्टरी वह लक्ष्य बन जाती है जिसे पुन: उत्पन्न करने के लिए मॉडल को फाइन-ट्यून किया जाता है।trajectory_dpo.jsonlमें प्रत्येक संपादित ट्रेस के लिए एक पंक्ति होती है,{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}। मानव का संपादन वरीयता को परिभाषित करता है: सुधारित को मूल से ऊपर।
 संपादन कैसे SFT और DPO प्रशिक्षण डेटा बनते हैं
संपादन कैसे SFT और DPO प्रशिक्षण डेटा बनते हैं
DPO फ़ाइल वह हिस्सा है जो मुफ़्त में मिल जाता है। एक सामान्य वरीयता-डेटा पाइपलाइन में आपको बेहतर प्रतिक्रिया के साथ जोड़ने के लिए एक बदतर प्रतिक्रिया उत्पन्न या एकत्र करनी पड़ती है। यहाँ बदतर प्रतिक्रिया पहले से मौजूद है (वह मूल ट्रैजेक्टरी है जो एजेंट ने उत्पन्न की) और मानव का संपादन इस बात का प्रमाण है कि सुधारित संस्करण को वरीयता दी जाती है। एक ही एनोटेशन से SFT लक्ष्य और DPO जोड़ा दोनों प्राप्त होते हैं।
क्या छोड़ा जाता है, और यह क्यों मायने रखता है
असंपादित ट्रेस गिनी तो जाती हैं पर SFT और DPO फ़ाइलों से बाहर रखी जाती हैं। एक अपरिवर्तित ट्रैजेक्टरी पर प्रशिक्षण मॉडल को कुछ नहीं सिखाता, और इससे भी बुरा यह कि वह वरीयता डेटासेट को chosen == rejected जोड़ों से भर देगा जो शोर जोड़ते हैं। छोड़ी गई की गिनती फिर भी निर्यात आँकड़ों में दिखाई देती है, इसलिए आप देख सकते हैं कि बैच का कितना हिस्सा पहले से ही सही था — यह स्वयं एजेंट गुणवत्ता के बारे में एक उपयोगी संकेत है। कई एनोटेटर होने पर, किसी दी गई ट्रेस को संपादित करने वाला हर एनोटेटर एक SFT/DPO रिकॉर्ड उत्पन्न करता है, इसलिए सभी स्वतंत्र सुधार योगदान करते हैं।
कुछ नुकीले किनारे
- डिफ़ शब्द-स्तरीय है। बिना रिक्त स्थान वाली कोड-जैसी tool call (टूल कॉल) के लिए, एक अकेला टोकन एक-अक्षर के सुधार पर भी पूरी तरह बदला हुआ दिख सकता है। ऐसे मामलों में अक्षर-दूरी काउंटर सटीक संकेत है; सघन टूल कॉल के लिए दृश्य डिफ़ की तुलना में उस पर भरोसा करें।
- संपादन स्वाभाविक रूप से स्कोरिंग के साथ जुड़ता है। यदि आप उसी ट्रेस पर प्रति-चरण शुद्धता लेबल या त्रुटि वर्गीकरण भी चाहते हैं, तो संपादक के साथ-साथ एक चरण-स्तरीय स्कोरिंग स्कीमा चलाएँ, ताकि एक ही पास निदान और सुधार दोनों उत्पन्न करे।
यह क्यों मायने रखता है
एजेंट-ट्यूनिंग लूप में हमेशा "इसे क्या करना चाहिए था" वाले चरण पर एक अड़चन रही है। स्कोर आपको बताते हैं कि मॉडल कहाँ विफल होता है; वे प्रशिक्षण के लिए सुधारित व्यवहार उत्पन्न नहीं करते, इसलिए टीमें अंततः कृत्रिम सुधार लिखने या दूसरे लेबलिंग पास के लिए भुगतान करने पर मजबूर हो जाती हैं। ट्रैजेक्टरी संपादन इसे मूल्यांकन के भीतर ही समेट लेता है। वही व्यक्ति जो ट्रेस को स्कोर देता, उसके बजाय उसकी मरम्मत करता है, और वह मरम्मत ही प्रशिक्षण डेटा है।
ट्रैजेक्टरी संपादन Potato 2.6 में आता है। विकल्पों की पूरी सूची के लिए ट्रैजेक्टरी संपादन दस्तावेज़ देखें, संपादन से पहले ट्रेस को तेज़ी से पढ़ने के लिए eval_trace प्रदर्शन देखें, और निर्यातक के विवरण के लिए निर्यात प्रारूप संदर्भ देखें।