Potato में गुणात्मक कोडिंग: कोडबुक, मेमो और इन-विवो कोड
QDA मोड पर एक नज़र, जो Potato 2.6 में आने वाला गुणात्मक डेटा विश्लेषण वर्कस्पेस है: एक जीवंत कोडबुक, इन-विवो कोडिंग, विश्लेषणात्मक मेमो, केस, और पूरे कॉर्पस पर पूर्ण-पाठ खोज।
अगर आपने कभी साक्षात्कार के ट्रांसक्रिप्ट को कोड किया है, तो आप सॉफ़्टवेयर की कहानी जानते हैं। गुणात्मक डेटा विश्लेषण (QDA) के लिए बने गंभीर उपकरण, जैसे NVivo, ATLAS.ti, MAXQDA और Dedoose, सक्षम तो हैं पर महंगे हैं। वे डेस्कटॉप पर रहते हैं, आपके प्रोजेक्ट को एक स्वामित्व-वाली फ़ाइल में बंद कर देते हैं, और सहयोग को लाइसेंस की सौदेबाज़ी में बदल देते हैं। बहुत-से शोधकर्ता अंततः किसी स्प्रेडशीट में ही कोडिंग करने लगते हैं, और फिर आधे रास्ते में ही सूत्र खो बैठते हैं, क्योंकि स्प्रेडशीट को यह पता ही नहीं होता कि कोड क्या होता है।
Potato बाड़ की दूसरी ओर से शुरू हुआ, NLP और मशीन-लर्निंग डेटासेट के लिए एक टेक्स्ट-एनोटेशन उपकरण के रूप में। पिछले कुछ रिलीज़ में इसने वे टुकड़े विकसित कर लिए जिनकी गुणात्मक वर्कफ़्लो को ज़रूरत होती है: अनुच्छेदों पर स्पैन, एक साझा कोडबुक, सहमति के मापदंड। आने वाली 2.6 रिलीज़ इन्हें एक ऐसे मोड में जोड़ देती है जो उस तरीके के लिए बना है जिस तरह गुणात्मक शोधकर्ता वास्तव में काम करते हैं।
यह पोस्ट QDA मोड के बारे में बताती है: यह क्या चालू करता है, टुकड़े आपस में कैसे जुड़ते हैं, और एक कॉन्फ़िग कैसी दिखती है। यदि आपको संदर्भ चाहिए, तो QDA मोड दस्तावेज़ीकरण में विकल्पों की पूरी सूची है।
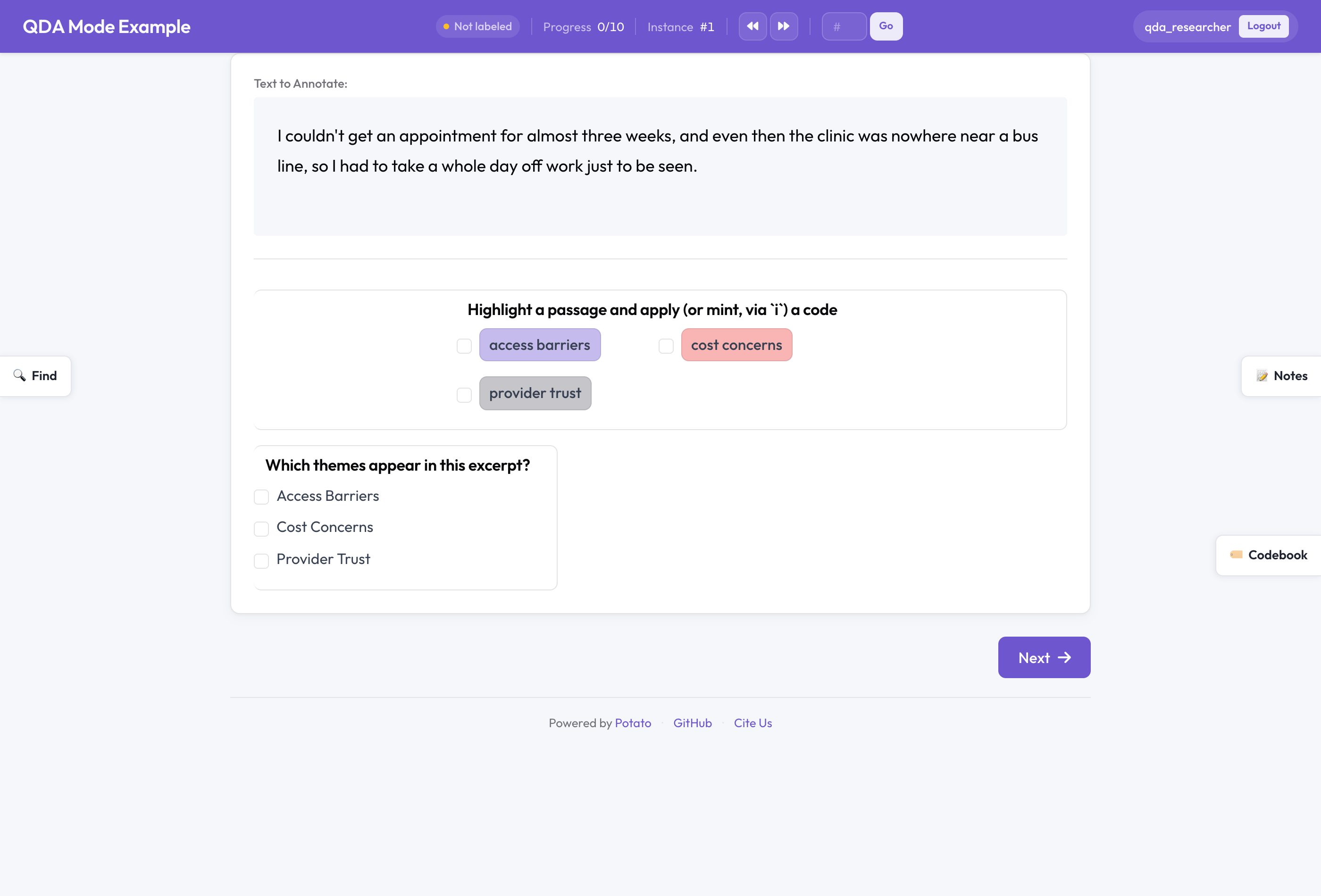 QDA मोड में Potato
QDA मोड में Potato
एक स्विच, गुणात्मक डिफ़ॉल्ट
Potato की अधिकांश मशीनरी बहुत भिन्न कार्यों में साझा होती है। वही स्पैन स्कीम जो किसी NER डेटासेट के लिए नामित इकाइयों को लेबल करती है, किसी साक्षात्कार के अनुच्छेदों को भी लेबल कर सकती है। इन दोनों कामों के बीच अंतर सुविधाओं का समूह नहीं, बल्कि रुख है। एक क्राउडसोर्स्ड NER प्रोजेक्ट एक तय लेबल-समूह चाहता है और सहमति मापने के लिए ओवरलैप सैंपलिंग। बीस साक्षात्कार अकेले कोड करने वाला शोधकर्ता पढ़ते-पढ़ते कोड गढ़ना चाहता है और जो देख रहा है उस पर निजी नोट्स रखना चाहता है।
QDA मोड वही एकमात्र स्विच है जो उस दूसरे रुख को मान लेता है:
qda_mode:
enabled: true # compose codebook + memos + cases + searchqda_mode.enabled: true सेट करने से Potato की सार्वभौमिक सुविधाएँ उनके गुणात्मक डिफ़ॉल्ट पर बदल जाती हैं। कोडबुक लॉक होने के बजाय कोडिंग के दौरान संपादन-योग्य हो जाती है। मेमो साइडबार चालू हो जाता है। केस स्वतः-पहचान के साथ चालू हो जाते हैं। जिस भी स्पैन स्कीम को आप कोडबुक-समर्थित चिह्नित करते हैं, उस पर इन-विवो कोडिंग उपलब्ध हो जाती है।
| सुविधा | मानक डिफ़ॉल्ट | QDA मोड के अंतर्गत |
|---|---|---|
| कोडबुक मोड | fixed | open: काम करते-करते कोड जोड़ें, नाम बदलें, रंग बदलें, हटाएँ या स्थानांतरित करें |
| मेमो साइडबार | बंद | चालू |
| केस | बंद | चालू, स्वतः-पहचान के साथ |
| एनोटेटर खोज-और-दावा | बंद | उपलब्ध (search.annotator_claim: true) |
| इन-विवो कोडिंग कुंजी | i | किसी भी कोडबुक-समर्थित स्पैन स्कीम पर सक्रिय |
इनमें से कुछ भी स्थायी रूप से तय नहीं है। QDA मोड केवल आरंभ-बिंदु बदलता है; हर डिफ़ॉल्ट को ओवरराइड किया जा सकता है। एकमात्र अपवाद एक सुरक्षा-घेरा है: यदि आप Prolific या Mechanical Turk जैसा कोई क्राउडसोर्सिंग बैकएंड जोड़ते हैं, तो Potato कोडबुक को बलपूर्वक fixed पर लॉक कर देता है, ताकि भुगतान-प्राप्त एनोटेटर आपके पीछे साझा स्कीम को बदल न सकें।
टुकड़े
एक जीवंत कोडबुक
ग्राउंडेड-थ्योरी शैली की कोडिंग में, कोडबुक वह चीज़ नहीं जिसे आप पहले से लिख डालते हैं। यह आपके पढ़ने के साथ बढ़ती है। आप किसी बार-बार आते विचार को पकड़ते हैं, उसे नाम देते हैं, और एक हफ़्ते बाद महसूस करते हैं कि आपके दो कोड दरअसल एक ही हैं, और उन्हें मिला देते हैं।
जब आप किसी स्पैन स्कीम को चिह्नित करते हैं, तो वह कोडबुक का हिस्सा बन जाती है:
annotation_schemes:
- annotation_type: span # span + codebook = qualitative coding
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]ये labels एक शुरुआती समूह हैं, पिंजरा नहीं। open कोडबुक मोड के अंतर्गत आप काम करते-करते कोड जोड़ते, नाम बदलते, रंग बदलते, स्थानांतरित करते और हटाते हैं। extensible मोड कोडर को कोड जोड़ने देता है पर साझा कोड हटाने नहीं देता; fixed वही लॉक किया गया क्लासिक है, उस समय के लिए जब आप किसी स्कीम पर अंतिम निर्णय ले चुके हों।
इन-विवो कोडिंग
इन-विवो कोडिंग प्रतिभागी के अपने शब्दों को ही कोड बना लेती है। कोई कहता है "मुझे तो जवाबी कॉल ही नहीं मिल पाई," और "जवाबी कॉल नहीं मिली" हू-ब-हू कोड बन जाता है।
किसी कोडबुक-समर्थित स्पैन स्कीम पर एक अनुच्छेद चुनें और इन-विवो कुंजी दबाएँ (codebook_invivo_key, डिफ़ॉल्ट i)। Potato हाइलाइट किए गए टेक्स्ट से सीधे एक कोड गढ़ देता है। जैसे-जैसे आप यह पूरे कॉर्पस में करते हैं, विखंडन ही शत्रु बन जाता है: आपके पास "कोई कॉल नहीं," "जवाबी कॉल नहीं मिली," और "कभी कॉल नहीं आई"—एक ही विचार के लिए तीन कोड हो जाते हैं। कोड कंपोज़र इसका प्रतिरोध करता है: टाइप करते समय यह लगभग-दोहरे कोड सामने ला देता है, ताकि आप नया कोड पैदा करने के बजाय किसी मौजूदा कोड का पुनः उपयोग करें।
मेमो
नोट्स के बिना कोडिंग कोड के पीछे के तर्क को खो देती है। मेमो किसी इंस्टेंस से या किसी विशिष्ट टेक्स्ट-चयन से जुड़े विश्लेषणात्मक नोट होते हैं। आप उन्हें निजी रख सकते हैं या टीम के साथ साझा कर सकते हैं। "मैंने इसे इस तरह क्यों कोड किया" का उत्तर यहीं बसता है, और ये उद्धरणों के साथ-साथ निर्यात होते हैं, ताकि प्रोजेक्ट के बाद भी आपका ऑडिट-ट्रेल बना रहे।
केस
एक केस अंशों को विश्लेषण की एक इकाई में समूहित करता है: एक प्रतिभागी, एक दस्तावेज़, एक स्थल-दौरा। एक बार अंश समूहित हो जाने पर, केस-स्तर के गुण ऊपर उठा लिए जाते हैं ताकि आप प्रतिभागी चरों के सापेक्ष कोड को सारणीबद्ध कर सकें। यदि हर साक्षात्कार में condition फ़ील्ड हो, तो एडमिन क्रॉसटैब दिखा सकता है कि कोई कोड विभिन्न परिस्थितियों में कैसे वितरित है।
cases:
enabled: true
key: participant_id
attributes: [condition]खोज
कोई कॉर्पस तभी नौगम्य होता है जब आप किसी शब्द के किसी भी उल्लेख पर कूद सकें। QDA मोड में पूरे डेटासेट पर FTS5 पूर्ण-पाठ खोज शामिल है। annotator_claim: true के साथ, कोई कोडर किसी भी खोज-मिलान को सीधे अपनी कतार में खींच सकता है, और इसी तरह एक अकेला विश्लेषक कॉर्पस को शुरू से अंत तक पढ़ने के बजाय विषय के अनुसार आगे बढ़ता है।
search:
enabled: true
annotator_claim: trueयह सब आपस में कैसे जुड़ता है
भीतर ही भीतर, कोडबुक, मेमो, केस और खोज—सभी एक ही प्रोजेक्ट डेटाबेस को पढ़ते और लिखते हैं, इसलिए किसी एक जगह गढ़ा गया कोड तुरंत हर दूसरी जगह खोजने-योग्य और निर्यात-योग्य हो जाता है।
 QDA मोड एक साझा स्टोर के ऊपर अपने टुकड़ों को कैसे जोड़ता है
QDA मोड एक साझा स्टोर के ऊपर अपने टुकड़ों को कैसे जोड़ता है
एक संपूर्ण कॉन्फ़िग
यहाँ एक छोटा पर संपूर्ण अध्ययन है। cases, search और मेमो ब्लॉक वैकल्पिक हैं (QDA मोड केस और मेमो पहले ही चालू कर देता है), इसलिए आप उन्हें केवल तभी लिखते हैं जब किसी डिफ़ॉल्ट को, जैसे केस कुंजी को, समायोजित करना हो।
annotation_task_name: My Qualitative Study
task_dir: .
output_annotation_dir: annotation_output/
data_files:
- data/interviews.json
item_properties:
id_key: id
text_key: text
qda_mode:
enabled: true
codebook_invivo_key: i
cases:
enabled: true
key: participant_id
attributes: [condition]
search:
enabled: true
annotator_claim: true
annotation_schemes:
- annotation_type: span
name: codes
description: Highlight a passage and apply (or mint, via `i`) a code
codebook: true
labels: [access barriers, cost concerns, provider trust]2.6 स्थापित हो जाने के बाद इसे रिपॉज़िटरी की जड़ से चलाएँ:
python potato/flask_server.py start examples/advanced/qda-mode-example/config.yaml -p 8000अपनी कोडिंग को वापस बाहर निकालना
दो निर्यातक कोड किए गए डेटा को उन वितरण-योग्य परिणामों में बदल देते हैं जिनकी किसी गुणात्मक शोध-पत्र को ज़रूरत होती है:
codebookप्रत्येक कोड के लिए एक पंक्ति देता है, उसके पदानुक्रम, विवरण, रंग और उपयोग-संख्या के साथ।quotation_reportप्रत्येक कोड किए गए स्पैन के लिए एक पंक्ति देता है: उद्धरण, उसके वर्ण-ऑफ़सेट, स्रोत इंस्टेंस, और कोडर। अपने मेमो जोड़ने के लिएinclude_memos=trueलगाएँ।
python -m potato.export config.yaml --format quotation_report \
--option include_memos=true -o quotations.csvयदि एक ही सामग्री को एक से अधिक व्यक्ति कोड करते हैं, तो आपको विश्वसनीयता का एक आँकड़ा चाहिए होगा। Potato कोड पर Cohen's और Fleiss' kappa की रिपोर्ट देता है, जो इन निर्यातकों के साथ 2.5 रिलीज़ में आया था।
यह कहाँ फिट बैठता है
QDA मोड हर पहलू पर NVivo से सुविधाओं में आगे निकलने की कोशिश नहीं करता। यह जो पेश करता है वह एक भिन्न सौदा है: मुफ़्त, ओपन सोर्स, वेब-आधारित, और सहयोगी, और यह उसी उपकरण के भीतर बैठा है जिसमें आपका मशीन-लर्निंग एनोटेशन और आपका एजेंट मूल्यांकन है। यदि आपकी प्रयोगशाला पहले से ही लेबलिंग के लिए Potato चला रही है, तो गुणात्मक कोडिंग अब किसी अलग लाइसेंस-प्राप्त डेस्कटॉप सॉफ़्टवेयर के बजाय बस एक कॉन्फ़िग ब्लॉक की दूरी पर है।
QDA मोड Potato 2.6 में आता है। पूर्ण दस्तावेज़ीकरण हर विकल्प को कवर करता है, और एनोटेटर-के-बीच सहमति गाइड विश्वसनीयता मापदंडों को समझाता है।