من التقييم إلى بيانات التدريب: تحرير المسارات من أجل SFT و DPO
تتوقف معظم عمليات تقييم الوكلاء عند درجة رقمية. يتيح مخطط trajectory_edit في Potato 2.6 للمُعلِّمين إعادة كتابة خطوة خاطئة بدلاً من تقييمها، ويُصدِّر كل تصحيح بوصفه أهدافاً للضبط الدقيق المُوجَّه وأزواج تفضيل لـ DPO.
عادةً ما ينتهي تقييم الوكلاء برقم. يقرأ المُعلِّم مساراً، فيقرّر أن الخطوة الثالثة كانت خاطئة، ثم يسجّل درجة منخفضة أو يضع وسماً بنوع الخطأ. هذا الرقم مفيد لقياس عدد مرات فشل الوكيل. لكنه أقل فائدة بكثير في إصلاح الوكيل، لأن عبارة "الخطوة الثالثة كانت خاطئة" لا تخبر النموذج بما كان ينبغي أن تكون عليه الخطوة الثالثة.
يضيف إصدار Potato 2.6 المرتقب مخططاً يطلب الإجابة بدلاً من الدرجة. مع trajectory_edit، يقوم المُعلِّمون بإعادة كتابة خطوات agent trace (مسار الوكيل) — بإصلاح خطوة استدلال فاشلة، أو إصلاح tool call (استدعاء أداة) أُخطئ في كتابته، أو تقوية إجابة نهائية ضعيفة — ويحتفظ Potato بالمسار المُصحَّح إلى جانب المسار الأصلي. ثم يحوِّل مُصدِّر trajectory_correction كل زوج (original, corrected) إلى بيانات تدريب: أهداف الضبط الدقيق المُوجَّه وأزواج تفضيل التحسين المباشر للتفضيل.
هذا هو التحوّل الذي تدور حوله هذه المقالة. فهو يحوّل أداة تقييم إلى أداة لإنتاج بيانات التدريب، ويغيّر ما يُنتجه وقت المُعلِّم البشري: ليس وسماً، بل إشارة تعلُّم.
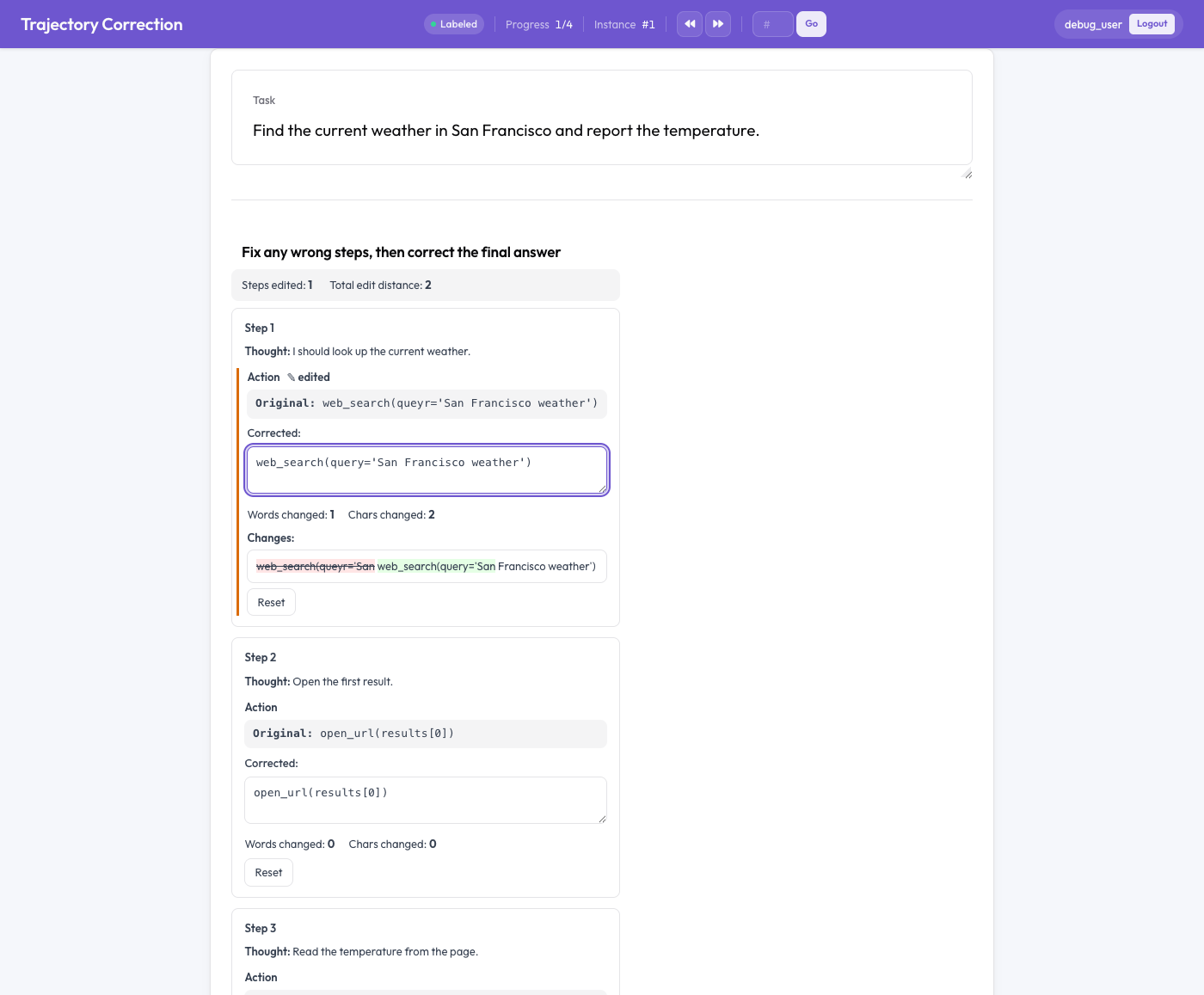 محرّر تصحيح المسارات
محرّر تصحيح المسارات
التحرير بدلاً من التقييم
تُعرض كل خطوة من خطوات الوكيل في صورة بطاقة من نصفين: النص الأصلي للقراءة فقط، ومربع التصحيح القابل للتحرير المُعبّأ مسبقاً بالنص الأصلي. يحرّر المُعلِّم مربع التصحيح مباشرة. وأثناء الكتابة، تحدث ثلاثة أشياء:
- تُبرز مقارنة فروق حيّة على مستوى الكلمات الإضافات باللون الأخضر والحذوفات بخط أحمر يشطب النص،
- تُحصى الكلمات والأحرف التي تغيّرت،
- وتظهر علامة "edited" (مُحرَّر) على أي حقل تغيّر.
يعيد زر "Reset" النص الأصلي لحقل ما إذا غيّر المُعلِّم رأيه. والأهم أن لا شيء إلزامي. فالمُعلِّم الذي يقرأ مساراً ويجده صحيحاً يتركه ببساطة كما هو، والمسار غير المُحرَّر لا يُنتج أي زوج تدريب. الإشارة تأتي فقط من التصحيحات الحقيقية.
الإعداد
يشير المخطط إلى قائمة الخطوات في بياناتك ويحدّد الحقول القابلة للتحرير:
annotation_schemes:
- annotation_type: trajectory_edit
name: corrected_trajectory
description: "Fix any wrong steps, then correct the final answer"
steps_key: steps # instance field holding the step list
step_text_key: action # the default per-step editable field
editable_fields: # which fields get an editor
- action
# - thought # add to also edit reasoning
show_diff: true
show_edit_distance: true
allow_reset: true
require_reason_on_edit: false # add a per-field "reason" input
edit_final_answer: true
final_answer_key: final_answerافتراضياً، يكون action في كل خطوة فقط قابلاً للتحرير. أضِف thought إلى editable_fields عندما تريد من المُعلِّمين إصلاح استدلال الوكيل إضافةً إلى أفعاله، واضبط require_reason_on_edit: true عندما تريد إرفاق تبرير مكتوب بكل تغيير، وهو ما يفيد عندما تخضع التصحيحات نفسها للمراجعة.
تنسيق البيانات هو ببساطة الشكل الذي تبدو عليه مساراتك أصلاً. يقرأ المخطط الخطوات من الحقل الذي يحدّده steps_key؛ وكل خطوة كائن يمكن تحرير حقوله:
{
"id": "traj_001",
"task_description": "Find the weather in San Francisco.",
"steps": [
{"thought": "Look it up.", "action": "web_search(queyr='SF weather')"},
{"thought": "Open it.", "action": "open_url(results[0])"}
],
"final_answer": "It is sunny."
}الخطأ الإملائي في queyr هو بالضبط نوع الأشياء التي يصلحها المُعلِّم في مربع التصحيح، فيُنتج تصحيحاً بمقدار رمز (token) واحد يمكن للنموذج أن يتعلّم منه.
شغّل المثال المرفق من جذر المستودع:
python potato/flask_server.py start examples/agent-traces/trajectory-correction/config.yaml -p 8000من التصحيحات إلى ملفات التدريب
يكتب مُصدِّر trajectory_correction ثلاثة ملفات، كل منها لاستخدام لاحق مختلف:
trajectory_corrections.jsonيحتفظ بالسجل الكامل:original_trace، وcorrected_traceالمُعاد بناؤه، وeditsلكل حقل مع مسافات التحرير والأسباب. هذا هو سجلّ التدقيق الخاص بك.trajectory_sft.jsonlيحوي سطراً واحداً لكل مسار مُحرَّر،{"prompt": <task>, "completion": <corrected_trace>}. يصبح المسار المُصحَّح هو الهدف الذي يُضبط النموذج بدقّة لإعادة إنتاجه.trajectory_dpo.jsonlيحوي سطراً واحداً لكل مسار مُحرَّر،{"prompt": <task>, "chosen": <corrected_trace>, "rejected": <original_trace>}. تحرير الإنسان يحدّد التفضيل: المُصحَّح مُفضَّل على الأصلي.
 كيف تتحوّل التحريرات إلى بيانات تدريب SFT و DPO
كيف تتحوّل التحريرات إلى بيانات تدريب SFT و DPO
ملف DPO هو الجزء الذي يأتي مجاناً. ففي خط أنابيب بيانات التفضيل المعتاد، عليك توليد أو جمع استجابة أسوأ لتقرنها بالاستجابة الأفضل. أما هنا فالاستجابة الأسوأ موجودة مسبقاً (وهي المسار الأصلي الذي أنتجه الوكيل)، وتحرير الإنسان هو الدليل على أن النسخة المُصحَّحة هي المُفضَّلة. تُنتج عملية تعليم واحدة هدف SFT وزوج DPO معاً.
ما الذي يُتخطّى، ولماذا يهمّ ذلك
تُحصى المسارات غير المُحرَّرة لكنها تُستبعَد من ملفي SFT و DPO. فالتدريب على مسار لم يتغيّر لا يعلّم النموذج شيئاً، بل والأسوأ أنه سيُغرِق مجموعة بيانات التفضيل بأزواج chosen == rejected تضيف ضوضاء. ويظل عدد المسارات المُتخطّاة يظهر في إحصاءات التصدير، فتستطيع أن ترى كم كانت نسبة الدفعة صحيحة بالفعل، وهذه في حدّ ذاتها إشارة مفيدة عن جودة الوكيل. ومع وجود عدة مُعلِّمين، يُنتج كل مُعلِّم حرّر مساراً بعينه سجلّ SFT/DPO واحداً، بحيث تساهم جميع التصحيحات المستقلة.
بعض الزوايا الحادة
- المقارنة على مستوى الكلمات. فبالنسبة لاستدعاءات الأدوات الشبيهة بالشيفرة وبلا مسافات، قد يظهر رمز (token) واحد وكأنه تغيّر بالكامل حتى لإصلاح من حرف واحد. عدّاد مسافة الأحرف هو الإشارة الدقيقة في هذه الحالات؛ ثِق به بدلاً من المقارنة المرئية في استدعاءات الأدوات المكتظّة.
- يقترن التحرير طبيعياً بـالتقييم. إن أردت أيضاً وسوم صحّة لكل خطوة أو تصنيفاً للأخطاء على المسار نفسه، فشغّل مخطط تقييم على مستوى الخطوة إلى جانب المحرّر، بحيث يُنتج مرور واحد كلاً من التشخيص والإصلاح.
لماذا يهمّ هذا
كان حلقة ضبط الوكلاء دائماً تعاني عنق زجاجة عند خطوة "ماذا كان ينبغي أن يفعل". تخبرك الدرجات أين يفشل النموذج؛ لكنها لا تُنتج السلوك المُصحَّح المطلوب للتدريب عليه، فينتهي الأمر بالفِرق إلى كتابة تصحيحات اصطناعية أو الدفع مقابل جولة وسم ثانية. تحرير المسارات يطوي ذلك داخل التقييم نفسه. فالإنسان نفسه الذي كان سيقيّم المسار يصلحه بدلاً من ذلك، والإصلاح هو بيانات التدريب.
تحرير المسارات يُشحَن في Potato 2.6. راجع توثيق تحرير المسارات للحصول على قائمة الخيارات الكاملة، وعرض eval_trace لقراءة المسارات بسرعة قبل التحرير، ومرجع تنسيقات التصدير لتفاصيل المُصدِّر.