Localização de Erros por Etapa: Usando Avaliação de Trajetória para Encontrar Onde os Agentes Falham
Use o esquema trajectory_eval do Potato para localização de erros por etapa, com taxonomias hierárquicas de erro, pontuação de severidade e acompanhamento de pontuação acumulada ao longo dos traços de agentes.
O problema: saber que um agente falhou não é suficiente
 A trajectory error taxonomy
A trajectory error taxonomy
Você executa seu agente em um benchmark. Ele atinge 63% de conclusão de tarefas. E agora?
Um número de aprovado/reprovado diz que o agente falhou em 37% das tarefas e nada mais. Ele não diz onde no traço as coisas deram errado, que tipo de erro o agente cometeu, nem quão grave foi. Foi um único erro catastrófico na etapa 2, ou quinze etapas de pequenos erros de raciocínio se acumulando? O agente usou uma ferramenta de forma errada, ou raciocinou a partir de uma premissa falsa?
Sem localização de erros por etapa, você não consegue diagnosticar os modos de falha, decidir o que corrigir primeiro, ou construir dados de treinamento para modelos de recompensa de processo. Você está ajustando hiperparâmetros no escuro.
O esquema de anotação trajectory_eval do Potato resolve isso. Os anotadores percorrem cada etapa de um traço e registram:
- Correção: esta etapa está correta ou incorreta?
- Tipo de erro: selecionado a partir de uma taxonomia hierárquica que você define
- Nível de severidade: menor, maior ou crítico, com pesos de pontuação configuráveis
- Justificativa: explicação em texto livre do erro (opcional)
- Pontuação acumulada: uma pontuação cumulativa que diminui conforme a severidade, fornecendo uma curva de qualidade por traço
Este guia cobre toda a configuração: definir sua taxonomia de erros, executar a anotação e analisar os dados coletados. Para a referência de configuração do esquema, consulte a documentação de origem.
Visão geral do esquema trajectory eval
O esquema trajectory_eval foi feito para avaliar traços de agentes de várias etapas em sequência. Em vez de uma única classificação geral de qualidade, ele produz uma anotação estruturada de erro para cada etapa, de modo que você termina com um mapa detalhado de onde e por que o agente falhou.
Veja o que a interface de anotação faz em cada etapa:
- O anotador vê o conteúdo da etapa atual (pensamento, ação, observação, código, etc.)
- Marca a etapa como correta ou incorreta
- Se incorreta, seleciona um tipo de erro a partir da taxonomia hierárquica
- Atribui um nível de severidade (menor, maior ou crítico)
- Opcionalmente, escreve uma justificativa explicando o erro
- A pontuação acumulada no topo da interface é atualizada automaticamente
O anotador avança pelo traço uma etapa de cada vez, montando um perfil de erro completo.
A interface de avaliação de trajetória mostra cada etapa com sua pontuação:
 Cada etapa recebe uma classificação de correção, um tipo de erro e um nível de severidade, com uma pontuação acumulada que diminui conforme a severidade
Cada etapa recebe uma classificação de correção, um tipo de erro e um nível de severidade, com uma pontuação acumulada que diminui conforme a severidade
Projetando uma taxonomia hierárquica de erros
A taxonomia é o que torna a avaliação de trajetória válida. Acerte nela e você consegue agregar erros entre traços e detectar padrões sistemáticos de falha; erre nela e seus rótulos não somam nada. Aqui está uma taxonomia da qual eu partiria, com quatro categorias de nível superior.
Erros de raciocínio
Eles ocorrem quando o raciocínio do agente é falho, mesmo que o que ele vê e faz esteja, no resto, em ordem.
| Tipo de Erro | Descrição | Exemplo |
|---|---|---|
logical_error | Inferência lógica inválida | "Como A implica B, e B é verdadeiro, A deve ser verdadeiro" (afirmação do consequente) |
incorrect_assumption | Assume algo não sustentado por evidências | Assume que um arquivo existe sem verificar |
over_generalization | Tira uma conclusão ampla demais a partir de evidências limitadas | "Esta função falhou uma vez, então toda a API está quebrada" |
circular_reasoning | A conclusão é usada como premissa | "A resposta é X porque X está correto" |
incorrect_calculation | Erro de cálculo matemático ou lógico | Erro de off-by-one no raciocínio do limite de um laço |
Erros de percepção
Eles ocorrem quando o agente lê errado, interpreta mal ou deixa passar informação em suas observações.
| Tipo de Erro | Descrição | Exemplo |
|---|---|---|
missed_element | Deixa de notar informação relevante | Ignora uma mensagem de erro na saída do terminal |
misidentified_element | Interpreta mal o que vê | Lê um erro 404 como uma resposta bem-sucedida |
hallucinated_element | Refere-se a algo que não está presente | Faz referência a um parâmetro de função que não existe |
outdated_reference | Usa informação desatualizada de uma etapa anterior | Usa o valor de uma variável que foi sobrescrita |
Erros de ação
Eles ocorrem quando o agente toma a ação errada, ou a ação certa da maneira errada.
| Tipo de Erro | Descrição | Exemplo |
|---|---|---|
wrong_tool | Seleciona uma ferramenta inadequada para a tarefa | Usa grep quando find é necessário |
wrong_arguments | Ferramenta correta, mas parâmetros incorretos | Passa o caminho de arquivo errado para um comando de edição |
premature_termination | Para antes de a tarefa estar concluída | Retorna uma resposta após encontrar informação parcial |
unnecessary_action | Toma uma ação que não agrega valor | Relê um arquivo que acabou de ser lido |
destructive_action | Toma uma ação que causa dano | Exclui um arquivo sem backup |
Erros de comunicação
Eles aparecem nas respostas do agente aos usuários ou na forma como ele narra o próprio trabalho.
| Tipo de Erro | Descrição | Exemplo |
|---|---|---|
unclear_explanation | A explicação é confusa ou ambígua | Descreve uma correção sem dizer o que estava quebrado |
missing_context | Omite contexto crítico da resposta | Relata sucesso sem mencionar ressalvas |
incorrect_summary | O resumo não corresponde às ações reais | Afirma ter editado 3 arquivos quando apenas 2 foram alterados |
overconfident_claim | Declara incerteza como certeza | "Isto vai resolver o problema com certeza" para uma mudança não testada |
Níveis de severidade e pesos de pontuação
Cada erro recebe um nível de severidade. Os pesos padrão são:
| Severidade | Peso | Descrição |
|---|---|---|
minor | -1 | Pequenos problemas que não descarrilam o traço (ex.: ação desnecessária, explicação pouco clara) |
major | -5 | Erros significativos que desperdiçam esforço ou produzem resultados parcialmente errados (ex.: ferramenta errada, suposição incorreta) |
critical | -10 | Erros que quebram fundamentalmente o traço (ex.: ação destrutiva, encerramento prematuro com resposta errada) |
A pontuação acumulada começa em 100 e cai pelo peso da severidade a cada erro. Um traço que termina em 85 teve alguns problemas menores; um que termina em 40 teve várias falhas maiores.
Você pode alterar esses pesos na configuração:
severity_levels:
- name: minor
weight: -1
description: "Small issue, does not derail the overall trace"
- name: major
weight: -5
description: "Significant error that wastes effort or produces wrong intermediate results"
- name: critical
weight: -10
description: "Fundamental failure that breaks the trace or causes harm"Configuração YAML completa
Aqui está um config.yaml completo para avaliação de trajetória com a taxonomia inteira:
annotation_task_name: "Agent Trajectory Error Localization"
data_files:
- "data/traces.jsonl"
item_properties:
id_key: "trace_id"
text_key: "task"
# Display agent traces with step-by-step rendering
display:
type: "agent_trace"
trace_key: "trace"
step_display:
thought: { label: "Thought", color: "#E8F0FE" }
action: { label: "Action", color: "#FFF3E0" }
observation: { label: "Observation", color: "#F1F8E9" }
code: { label: "Code", color: "#F3E5F5" }
annotation_schemes:
- annotation_type: "trajectory_eval"
name: "error_localization"
description: "Evaluate each step for correctness and classify any errors"
# Per-step correctness check
step_correctness:
labels: ["correct", "incorrect"]
default: "correct"
# Hierarchical error taxonomy (shown when step is marked incorrect)
error_taxonomy:
- category: "reasoning"
label: "Reasoning Error"
types:
- name: "logical_error"
label: "Logical Error"
description: "Invalid logical inference or deduction"
- name: "incorrect_assumption"
label: "Incorrect Assumption"
description: "Assumes something not supported by available evidence"
- name: "over_generalization"
label: "Over-generalization"
description: "Draws too broad a conclusion from limited evidence"
- name: "circular_reasoning"
label: "Circular Reasoning"
description: "Uses the conclusion as a premise"
- name: "incorrect_calculation"
label: "Incorrect Calculation"
description: "Mathematical or logical computation error"
- category: "perception"
label: "Perception Error"
types:
- name: "missed_element"
label: "Missed Element"
description: "Fails to notice relevant information in observations"
- name: "misidentified_element"
label: "Misidentified Element"
description: "Misinterprets what it observes"
- name: "hallucinated_element"
label: "Hallucinated Element"
description: "Refers to something not present in the context"
- name: "outdated_reference"
label: "Outdated Reference"
description: "Uses stale information from a previous step"
- category: "action"
label: "Action Error"
types:
- name: "wrong_tool"
label: "Wrong Tool"
description: "Selects an inappropriate tool for the task"
- name: "wrong_arguments"
label: "Wrong Arguments"
description: "Correct tool but incorrect parameters"
- name: "premature_termination"
label: "Premature Termination"
description: "Stops before the task is complete"
- name: "unnecessary_action"
label: "Unnecessary Action"
description: "Takes an action that adds no value"
- name: "destructive_action"
label: "Destructive Action"
description: "Takes an action that causes harm or data loss"
- category: "communication"
label: "Communication Error"
types:
- name: "unclear_explanation"
label: "Unclear Explanation"
description: "Explanation is confusing or ambiguous"
- name: "missing_context"
label: "Missing Context"
description: "Omits critical context from the response"
- name: "incorrect_summary"
label: "Incorrect Summary"
description: "Summary does not match the actual actions taken"
- name: "overconfident_claim"
label: "Overconfident Claim"
description: "States uncertain outcomes as certainties"
# Severity levels with score weights
severity_levels:
- name: "minor"
weight: -1
description: "Small issue, does not derail the overall trace"
- name: "major"
weight: -5
description: "Significant error that wastes effort or produces wrong results"
- name: "critical"
weight: -10
description: "Fundamental failure that breaks the trace or causes harm"
# Running score configuration
running_score:
initial: 100
min: 0
display: true
# Optional rationale field
rationale:
enabled: true
placeholder: "Explain why this step is incorrect..."
# Overall trace quality (optional, shown at the end)
- annotation_type: "radio"
name: "overall_success"
description: "Did the agent ultimately complete the task correctly?"
labels:
- name: "success"
tooltip: "Task completed correctly"
- name: "partial"
tooltip: "Task partially completed or completed with errors"
- name: "failure"
tooltip: "Task not completed or fundamentally wrong"
# Annotator settings
annotator_config:
allow_back_navigation: true
require_all_steps: true
# Output settings
output:
path: "output/"
format: "jsonl"Configuração passo a passo
1. Prepare os traços do seu agente
Os dados de traço vão em formato JSONL, um traço por linha. Cada traço precisa de um ID, uma descrição da tarefa e uma lista de etapas:
{
"trace_id": "trace_042",
"task": "Find the bug in the calculate_discount function and fix it",
"trace": [
{
"type": "thought",
"content": "I need to look at the calculate_discount function to find the bug. Let me search for it."
},
{
"type": "action",
"content": "search",
"action_input": "def calculate_discount"
},
{
"type": "observation",
"content": "Found in pricing.py line 45:\ndef calculate_discount(price, discount_pct):\n return price * discount_pct / 100"
},
{
"type": "thought",
"content": "The function calculates the discount amount but doesn't subtract it from the price. It should return price - (price * discount_pct / 100)."
},
{
"type": "action",
"content": "edit_file",
"action_input": "pricing.py:45: return price - (price * discount_pct / 100)"
},
{
"type": "observation",
"content": "File edited successfully."
},
{
"type": "action",
"content": "finish",
"action_input": "Fixed the calculate_discount function. It was returning the discount amount instead of the discounted price."
}
]
}Se seus traços estiverem em um formato diferente (mensagens da OpenAI, execuções do LangChain, logs de conversa do Claude), use o conversor de traços do Potato:
python -m potato.convert_traces \
--input raw_traces/ \
--output data/traces.jsonl \
--format react2. Configure sua taxonomia
Comece com a taxonomia completa acima, depois reduza ou estenda conforme seu agente. Para um agente de codificação, por exemplo, você poderia adicionar uma categoria code_quality:
- category: "code_quality"
label: "Code Quality Error"
types:
- name: "syntax_error"
label: "Syntax Error"
description: "Generated code has syntax errors"
- name: "runtime_error"
label: "Runtime Error"
description: "Code runs but produces an error"
- name: "logic_bug"
label: "Logic Bug"
description: "Code runs without errors but produces wrong output"
- name: "style_violation"
label: "Style Violation"
description: "Code works but violates project conventions"Para traços de agentes de codificação, a avaliação renderiza diffs e saída de terminal ao lado da pontuação:
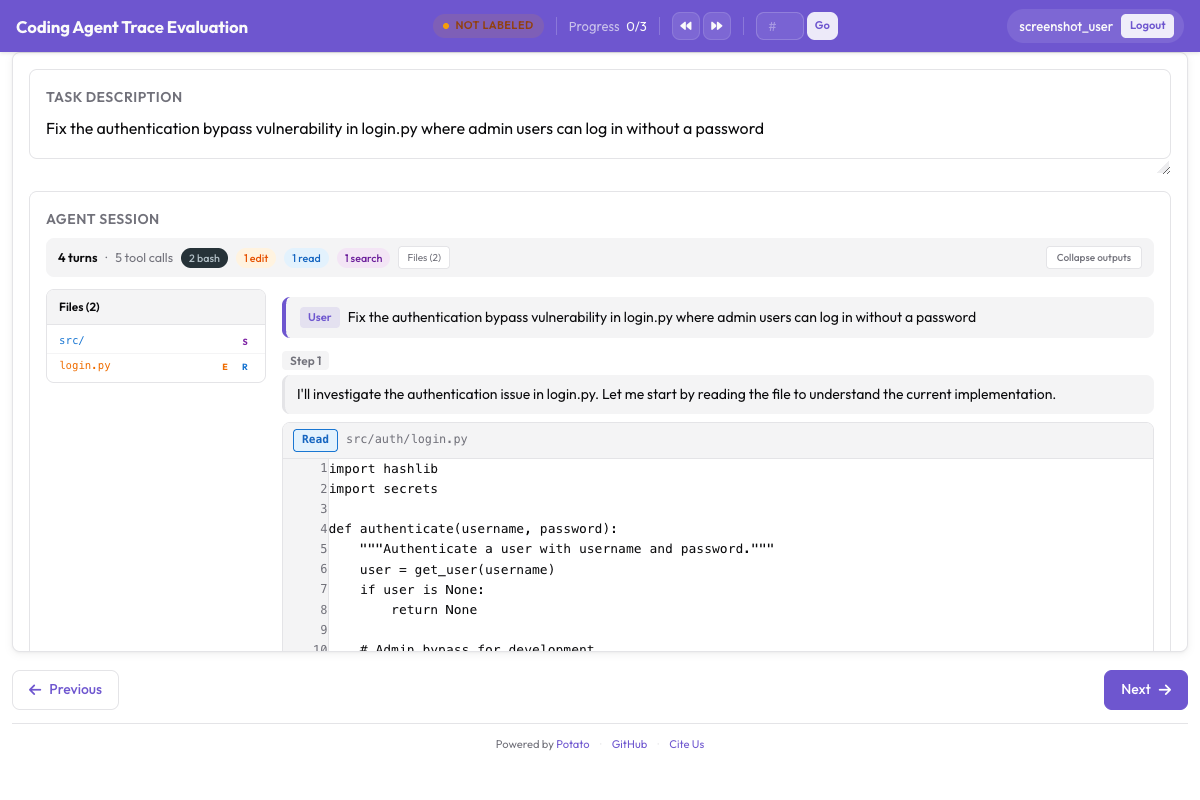 O CodingTraceDisplay renderiza diffs, blocos de terminal e leituras de arquivo ao lado dos controles de avaliação de trajetória
O CodingTraceDisplay renderiza diffs, blocos de terminal e leituras de arquivo ao lado dos controles de avaliação de trajetória
3. Inicie o servidor de anotação
potato start config.yaml -p 8000Abra http://localhost:8000 no seu navegador. Você verá o primeiro traço com a exibição passo a passo.
4. Escreva as diretrizes de anotação
Dê aos anotadores instruções claras. No mínimo, documente:
- Quando marcar uma etapa como incorreta vs. correta-mas-subótima
- Como escolher entre categorias de erro quando várias se aplicam (use a mais específica)
- Quando atribuir cada nível de severidade, com exemplos concretos
- Se as etapas devem ser avaliadas com base na informação disponível naquela etapa ou com retrospectiva
O fluxo de anotação
Quando um anotador abre um traço, a descrição da tarefa fica no topo e a primeira etapa fica abaixo dela. A pontuação acumulada marca 100 no canto superior direito.
Para cada etapa, o anotador:
- Lê o conteúdo da etapa no contexto das etapas anteriores
- Marca a correção clicando em "Correct" ou "Incorrect"
- Se incorreta, seleciona a categoria de erro (ex.: "Reasoning Error") e depois o tipo específico (ex.: "Incorrect Assumption")
- Atribui a severidade: menor, maior ou crítica
- Escreve uma justificativa (se habilitada): "O agente assume que o arquivo está no diretório atual sem verificar, mas os resultados da busca mostraram que ele está em src/utils/"
- Avança para a próxima etapa clicando em "Next Step" ou pressionando a seta para a direita
A pontuação acumulada é atualizada após cada erro. Marque a etapa 3 como um erro maior (-5) e a pontuação cai de 100 para 95. Marque a etapa 7 como crítica (-10) e ela cai para 85.
Ao final do traço, o anotador atribui a classificação geral de sucesso/parcial/falha e envia.
Analisando os resultados
Carregando dados de anotação
import json
import pandas as pd
from collections import Counter
from pathlib import Path
# Load all annotation files
annotations = []
output_dir = Path("output/")
for f in output_dir.glob("*.jsonl"):
with open(f) as fh:
for line in fh:
annotations.append(json.loads(line))
print(f"Loaded {len(annotations)} annotated traces")Análise da distribuição de erros
# Extract all errors across all traces
errors = []
for ann in annotations:
for step_ann in ann.get("error_localization", []):
if step_ann["correctness"] == "incorrect":
errors.append({
"trace_id": ann["trace_id"],
"step_index": step_ann["step_index"],
"category": step_ann["error_category"],
"error_type": step_ann["error_type"],
"severity": step_ann["severity"],
"rationale": step_ann.get("rationale", ""),
})
error_df = pd.DataFrame(errors)
print(f"Total errors found: {len(error_df)}")
print()
# Error distribution by category
print("Errors by category:")
print(error_df["category"].value_counts())
print()
# Most common specific error types
print("Top 10 error types:")
print(error_df["error_type"].value_counts().head(10))
print()
# Severity distribution
print("Severity distribution:")
print(error_df["severity"].value_counts())Análise da posição dos erros
Ver onde num traço os erros tendem a cair muitas vezes revela padrões sistemáticos:
import matplotlib.pyplot as plt
import numpy as np
# Normalize step positions to [0, 1] range
for ann in annotations:
trace_length = len(ann.get("error_localization", []))
for step_ann in ann["error_localization"]:
if step_ann["correctness"] == "incorrect":
step_ann["normalized_position"] = step_ann["step_index"] / max(trace_length - 1, 1)
# Collect normalized positions
positions = [
step_ann["normalized_position"]
for ann in annotations
for step_ann in ann.get("error_localization", [])
if step_ann["correctness"] == "incorrect"
and "normalized_position" in step_ann
]
plt.figure(figsize=(10, 4))
plt.hist(positions, bins=20, edgecolor="black", alpha=0.7)
plt.xlabel("Normalized Position in Trace (0 = start, 1 = end)")
plt.ylabel("Error Count")
plt.title("Where Do Agent Errors Occur?")
plt.tight_layout()
plt.savefig("error_position_distribution.png", dpi=150)
print("Saved error_position_distribution.png")Distribuições da pontuação acumulada
# Extract final running scores
final_scores = []
for ann in annotations:
score = 100
severity_weights = {"minor": -1, "major": -5, "critical": -10}
for step_ann in ann.get("error_localization", []):
if step_ann["correctness"] == "incorrect":
score += severity_weights.get(step_ann["severity"], 0)
score = max(score, 0)
final_scores.append({
"trace_id": ann["trace_id"],
"final_score": score,
"overall_success": ann.get("overall_success", "unknown"),
})
score_df = pd.DataFrame(final_scores)
print("Score statistics:")
print(score_df["final_score"].describe())
print()
# Score distribution by overall success
for label in ["success", "partial", "failure"]:
subset = score_df[score_df["overall_success"] == label]
if len(subset) > 0:
print(f"{label}: mean={subset['final_score'].mean():.1f}, "
f"median={subset['final_score'].median():.1f}, "
f"n={len(subset)}")Modos de falha mais comuns
# Group errors by category + type for a failure mode analysis
failure_modes = (
error_df.groupby(["category", "error_type"])
.agg(
count=("severity", "size"),
avg_severity_weight=("severity", lambda x: x.map(
{"minor": 1, "major": 5, "critical": 10}
).mean()),
)
.sort_values("count", ascending=False)
)
print("Top failure modes (by frequency):")
print(failure_modes.head(15).to_string())
print()
# Impact-weighted failure modes (frequency x average severity)
failure_modes["impact"] = failure_modes["count"] * failure_modes["avg_severity_weight"]
print("Top failure modes (by impact):")
print(failure_modes.sort_values("impact", ascending=False).head(10).to_string())Contexto de pesquisa
A localização de erros por etapa se alinha a algumas linhas recentes de pesquisa em avaliação de agentes:
O TRAIL Benchmark (Patronus AI, 2025) levou adiante a ideia de avaliar trajetórias de agentes em vez de apenas resultados, e mostrou que os agentes falham em padrões previsíveis que as métricas de nível de resultado deixam passar por completo. O esquema trajectory_eval é uma forma de coletar esses rótulos detalhados de nível de etapa em escala.
O AgentRewardBench montou benchmarks para modelos de recompensa de processo (PRMs) que pontuam etapas individuais de raciocínio. Os rótulos de correção e severidade por etapa do trajectory_eval se encaixam direto no treinamento de PRMs: cada etapa anotada é um exemplo de treinamento com um sinal de qualidade de referência.
O artigo "Demystifying Evals for AI Agents" (2025) da Anthropic argumentou que a avaliação de agentes deveria focar na qualidade da trajetória, e não apenas em saber se a resposta final estava certa. Os modos de falha que eles destacam (encerramento prematuro, uso incorreto de ferramentas, erros de raciocínio) mapeiam diretamente nas categorias da taxonomia deste guia.
A pontuação acumulada ponderada por severidade também se mapeia nos sinais de recompensa usados em RLHF. Uma curva de pontuação que cai bruscamente na etapa 5 de um traço de 20 etapas diz exatamente onde o agente precisa de trabalho, o que é bem mais acionável do que uma única recompensa ao final do traço.
Resumo
O esquema trajectory_eval transforma a avaliação de agentes de uma verificação de aprovado/reprovado em um diagnóstico. Com uma taxonomia hierárquica, pontuação de severidade e uma pontuação acumulada, você consegue ver qual etapa deu errado, que tipo de erro foi, quão grave foi e onde os erros tendem a se concentrar entre os traços. Os rótulos de nível de etapa também já estão prontos para uso como dados de treinamento de modelos de recompensa de processo.
Comece com a taxonomia completa deste guia, depois refine-a para o seu agente e para os padrões de erro que você realmente observa. A melhor taxonomia é aquela que aponta para correções que você consegue fazer.