Como coletar dados de recompensa de processo para treinar agentes de codificação melhores
Guia passo a passo para coletar sinais de recompensa por etapa para treinamento de PRM usando o Potato. Cobre o modo primeiro-erro, anotação por etapa e exportação para pipelines de treinamento.
O que são modelos de recompensa de processo?
 Two ways to label process rewards
Two ways to label process rewards
Os modelos de recompensa de resultado (ORMs) olham apenas para o final da trajetória de um agente de codificação: o código compilou, os testes passaram, o problema foi resolvido? Os modelos de recompensa de processo (PRMs) pontuam cada etapa intermediária em vez disso. Com um sinal de recompensa em cada etapa, os métodos de treinamento conseguem identificar onde um agente errou, o que tende a tornar o aprendizado mais eficiente em amostras e ajuda na generalização.
Trabalhos recentes confirmam isso. O AgentPRM relatou que sinais de recompensa por etapa melhoram o desempenho do agente no SWE-bench em 12-18% em relação à supervisão somente por resultado. O ToolRM descobriu que recompensas por chamada de ferramenta ajudam os agentes a aprender quais ferramentas usar e quando. O DeepSWE combinou recompensas de processo com busca em árvore de Monte Carlo para resultados de ponta em tarefas difíceis de engenharia de software.
O que todos eles precisam é de boa anotação humana por etapa, e isso costuma ser o gargalo. Os esquemas de recompensa de processo do Potato são feitos para tornar a coleta desses dados mais rápida. Para o esquema subjacente, veja a documentação de avaliação de trajetória e, para detalhes de entrada de traces, a documentação de traces de agentes.
Dois modos de anotação
O Potato tem dois modos de anotação para PRM que trocam velocidade por granularidade. Escolha o que se encaixa no seu orçamento de dados e nos seus objetivos.
Modo primeiro-erro
No modo primeiro-erro, o anotador lê a trajetória de cima para baixo e clica na primeira etapa em que o agente comete um erro. O Potato então marca toda etapa anterior como correta e toda etapa a partir da clicada como incorreta.
Isso é rápido porque o anotador só precisa encontrar um único ponto de decisão. Funciona bem quando os erros se propagam em cascata, ou seja, quando um agente sai do rumo ele raramente se recupera, que é o caso comum na prática.
annotation_schemes:
- annotation_type: process_reward
name: prm_first_error
mode: "first_error"
labels:
correct: "Correct"
incorrect: "Incorrect"
description: >
Review the agent's steps from top to bottom. Click on the
first step where the agent makes a mistake. All steps before
your selection will be marked correct; all steps after
(including the selected step) will be marked incorrect.
allow_all_correct: true
allow_all_incorrect: true
highlight_clicked_step: true
auto_scroll_on_click: true
show_step_numbers: true
confirmation_dialog: true # Confirm before submittingO fluxo de anotação no modo primeiro-erro fica assim:
- O anotador abre um trace e vê todas as etapas renderizadas com o componente CodingTraceDisplay.
- Ele lê as etapas sequencialmente, examinando diffs, saídas de terminal e raciocínio.
- Quando encontra a primeira etapa incorreta, clica no marcador de erro ao lado dela.
- As etapas de 0 a N-1 ficam verdes (correto), e as etapas de N até o final ficam vermelhas (incorreto).
- O anotador revisa a rotulagem automática e clica em "Submit" para confirmar.
Se o trace inteiro estiver correto (o agente resolveu a tarefa perfeitamente), o anotador clica em "All Correct". Se a primeira etapa já estiver errada, ele clica na etapa 0 ou usa "All Incorrect".
Aqui está a interface de anotação de PRM em ação:
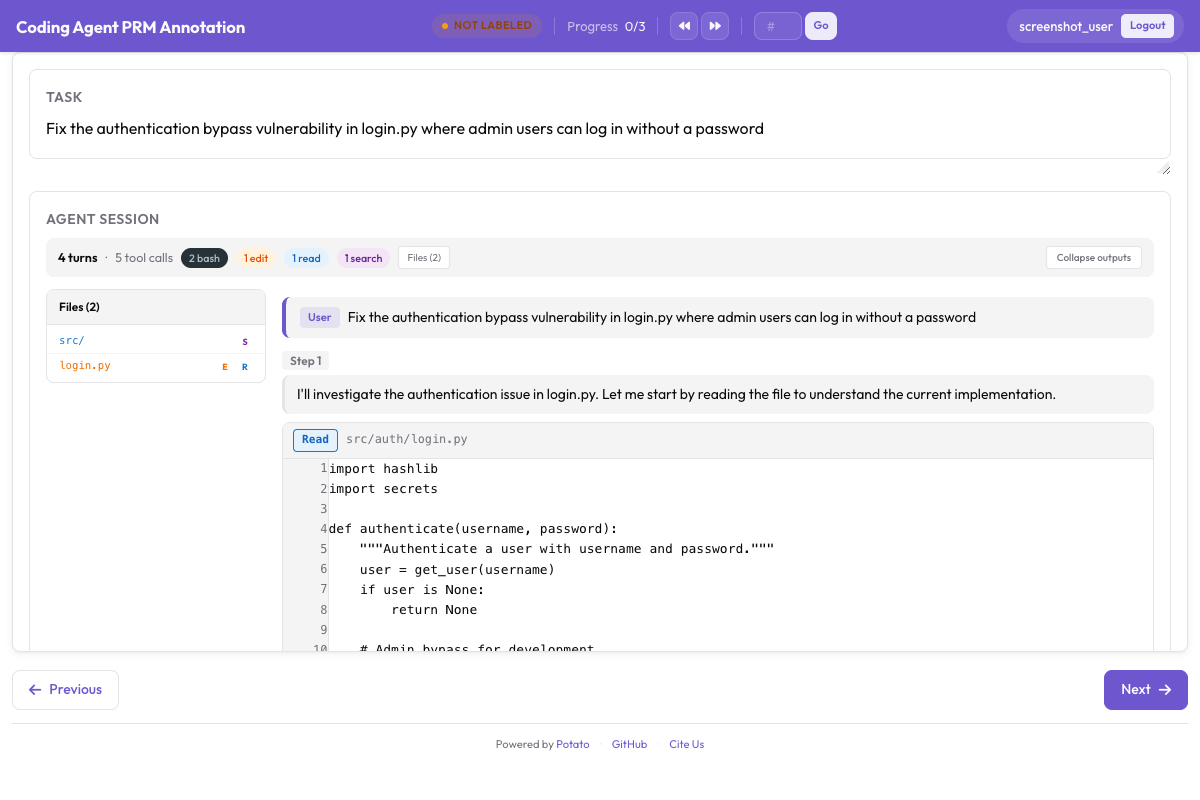 No modo primeiro-erro, clique na primeira etapa incorreta e todas as etapas seguintes são marcadas automaticamente
No modo primeiro-erro, clique na primeira etapa incorreta e todas as etapas seguintes são marcadas automaticamente
Modo por etapa
No modo por etapa, cada etapa recebe o seu próprio rótulo. Isso produz dados mais ricos, já que captura casos em que um agente se recupera parcialmente de um erro, faz um desvio inofensivo mas desnecessário, ou dá um passo que é correto isoladamente, mas errado no contexto.
annotation_schemes:
- annotation_type: process_reward
name: prm_per_step
mode: "per_step"
labels:
correct:
text: "Correct"
description: >
This step is logically sound, makes progress toward the goal,
and does not introduce bugs or unnecessary complexity.
keyboard_shortcut: "1"
color: "#22c55e"
partially_correct:
text: "Partially Correct"
description: >
This step is in the right direction but has flaws: incomplete
fix, unnecessary side effects, suboptimal approach, or missing
edge cases.
keyboard_shortcut: "2"
color: "#eab308"
incorrect:
text: "Incorrect"
description: >
This step is wrong, counterproductive, or introduces new bugs.
The agent should not have taken this action.
keyboard_shortcut: "3"
color: "#ef4444"
neutral:
text: "Neutral"
description: >
This step neither helps nor hurts. Includes reading files for
context or running diagnostic commands.
keyboard_shortcut: "4"
color: "#94a3b8"
require_all_steps: true
show_progress_bar: true
enable_keyboard_navigation: true
step_navigation:
next_step: "j"
previous_step: "k"
next_unlabeled: "n"Configurando um projeto de anotação de PRM
Etapa 1: prepare os dados de trace
Os seus dados de entrada devem ser um arquivo JSONL em que cada linha é um objeto JSON contendo a trajetória do agente. Os campos-chave são id, issue_description e structured_turns:
{
"id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"repo": "myorg/myproject",
"base_commit": "a1b2c3d",
"structured_turns": [
{
"step_idx": 0,
"type": "thinking",
"content": "I need to understand what parse_config does and where the TypeError occurs. Let me read the file first."
},
{
"step_idx": 1,
"type": "file_read",
"path": "src/config.py",
"content": "def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n return data['settings']",
"start_line": 1,
"end_line": 4
},
{
"step_idx": 2,
"type": "thinking",
"content": "The bug is on line 4. When the file is empty, json.load returns None, and None['settings'] raises TypeError. I should add a check."
},
{
"step_idx": 3,
"type": "file_edit",
"path": "src/config.py",
"diff": "--- a/src/config.py\n+++ b/src/config.py\n@@ -1,4 +1,6 @@\n def parse_config(path):\n with open(path) as f:\n data = json.load(f)\n+ if data is None:\n+ return {}\n return data['settings']"
},
{
"step_idx": 4,
"type": "bash_command",
"command": "python -m pytest tests/test_config.py -v",
"output": "tests/test_config.py::test_parse_config_empty PASSED\ntests/test_config.py::test_parse_config_valid PASSED\n\n2 passed in 0.12s",
"exit_code": 0
}
]
}Se você está convertendo de um formato de agente existente, use a ferramenta de conversão de traces:
# Convert Claude Code traces
potato convert-traces \
--format claude_code \
--input ./raw_traces/ \
--output ./data/traces.jsonl
# Convert SWE-Agent trajectories
potato convert-traces \
--format swe_agent \
--input ./swe_agent_output/ \
--output ./data/traces.jsonlO Potato renderiza traces de agentes de codificação com realce de diff adequado:
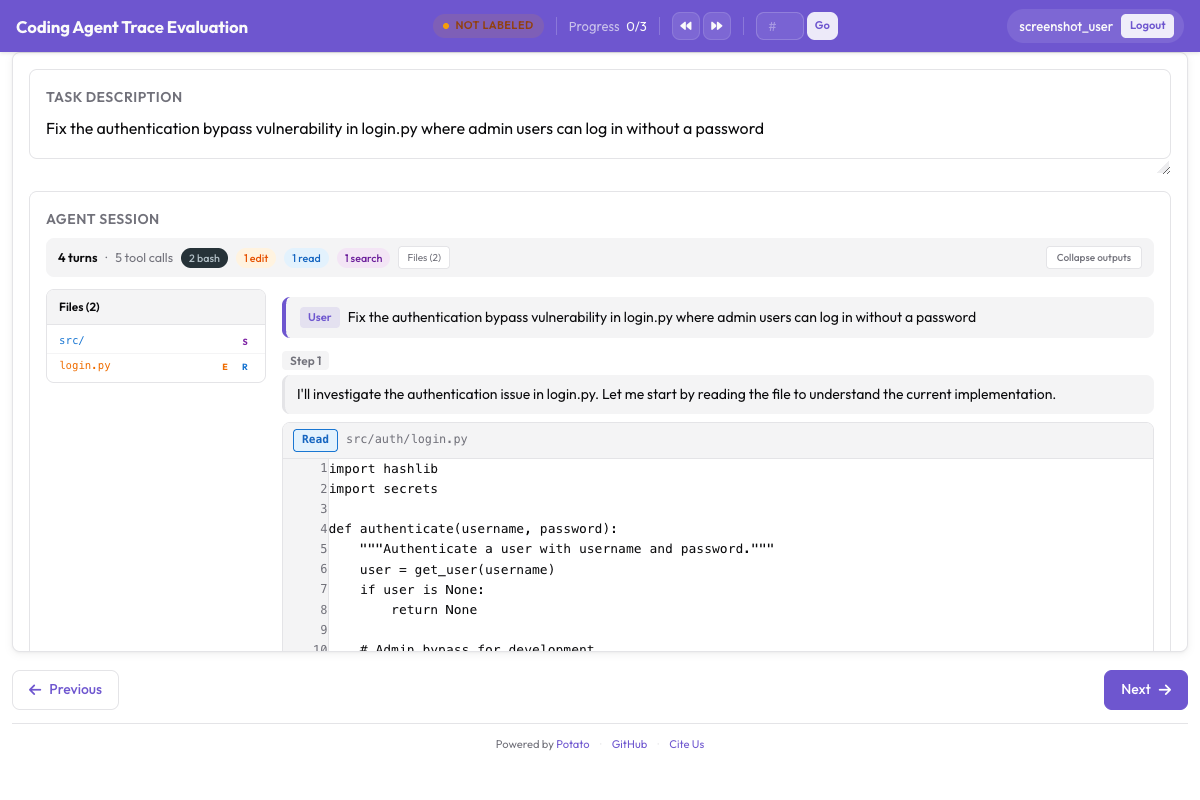 Diffs de código, saída de terminal e leituras de arquivo são renderizados com realce de sintaxe
Diffs de código, saída de terminal e leituras de arquivo são renderizados com realce de sintaxe
Etapa 2: crie a sua configuração
Aqui está uma configuração completa de projeto para anotação de PRM usando o modo primeiro-erro:
# config.yaml
project_name: "PRM Data Collection - SWE-bench Traces"
port: 8000
data:
source: "local"
input_path: "./data/traces.jsonl"
data_format: "coding_trace"
coding_agent:
display:
diff_style: "unified"
context_lines: 3
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
position: "left"
collapsible:
auto_collapse_thinking: true
auto_collapse_long_output: true
long_output_threshold: 50
annotation_schemes:
- annotation_type: process_reward
name: step_reward
mode: "first_error"
labels:
correct: "Correct Step"
incorrect: "Incorrect Step"
allow_all_correct: true
allow_all_incorrect: true
description: >
Review the agent's trajectory step by step. Click the first
step where the agent makes an error. If the entire trajectory
is correct, click "All Correct."
highlight_clicked_step: true
confirmation_dialog: true
- annotation_type: radio
name: outcome
label: "Did the agent resolve the issue?"
options:
- value: "resolved"
text: "Fully Resolved"
- value: "partial"
text: "Partially Resolved"
- value: "not_resolved"
text: "Not Resolved"
- annotation_type: text_input
name: error_description
label: "If incorrect, briefly describe the error"
placeholder: "e.g., Agent edited the wrong file..."
required: false
show_if:
field: "step_reward"
condition: "has_error"
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 15
minimum_time_per_instance: 20
annotators:
- username: "reviewer1"
password: "pw_reviewer1"
- username: "reviewer2"
password: "pw_reviewer2"
- username: "reviewer3"
password: "pw_reviewer3"Etapa 3: inicie o servidor de anotação
# Start the annotation server
potato start config.yaml -p 8000
# Or run in the background
nohup potato start config.yaml -p 8000 > potato.log 2>&1 &Navegue até http://localhost:8000, faça login com uma das contas de anotador configuradas e comece a revisar os traces.
Etapa 4: acompanhe o progresso
Enquanto a anotação está em andamento, acompanhe o progresso e a concordância:
# Check annotation progress
potato status config.yaml
# View inter-annotator agreement
potato agreement config.yaml --metric krippendorff_alphaExportando para formatos de treinamento
Assim que a anotação estiver concluída, exporte os dados no formato que o seu pipeline de treinamento espera.
Formato PRM para treinamento de modelo de recompensa
O formato de exportação PRM produz um objeto JSON por trace com rótulos por etapa:
potato export \
--format prm \
--project ./output/ \
--output ./training_data/prm_labels.jsonlA saída fica assim:
{
"trace_id": "trace_001",
"issue_description": "Fix the TypeError in parse_config() when config file is empty",
"total_steps": 5,
"first_error_step": null,
"all_correct": true,
"steps": [
{"step_idx": 0, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 1, "type": "file_read", "label": "correct", "reward": 1.0},
{"step_idx": 2, "type": "thinking", "label": "correct", "reward": 1.0},
{"step_idx": 3, "type": "file_edit", "label": "correct", "reward": 1.0},
{"step_idx": 4, "type": "bash_command", "label": "correct", "reward": 1.0}
]
}Pares de preferência para DPO/RLHF
Quando você tem múltiplos traces para o mesmo problema (por exemplo, de agentes diferentes ou execuções diferentes), o Potato pode gerar pares de preferência com base nos rótulos de PRM:
potato export \
--format preference_pairs \
--project ./output/ \
--output ./training_data/preferences.jsonl \
--pair_by "issue_id"A exportação de pares de preferência compara traces que tentaram a mesma tarefa e seleciona o melhor com base nos rótulos por etapa:
{
"prompt": "Fix the TypeError in parse_config() when config file is empty",
"chosen_trace_id": "trace_001",
"rejected_trace_id": "trace_002",
"chosen_first_error": null,
"rejected_first_error": 3,
"chosen_steps": 5,
"rejected_steps": 7,
"margin": 0.8
}Resultados compatíveis com SWE-bench
Exporte no formato SWE-bench para benchmarking:
potato export \
--format swe_bench \
--project ./output/ \
--output ./training_data/swe_bench_results.jsonExemplos de análise
Após coletar as anotações, use estes trechos de Python para analisar os dados e identificar padrões.
Acurácia por etapa segundo o tipo de etapa
import json
from collections import defaultdict
# Load PRM annotations
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Compute accuracy by step type
type_stats = defaultdict(lambda: {"correct": 0, "total": 0})
for trace in traces:
for step in trace["steps"]:
step_type = step["type"]
type_stats[step_type]["total"] += 1
if step["label"] == "correct":
type_stats[step_type]["correct"] += 1
print("Step-Level Accuracy by Type:")
print("-" * 45)
for step_type, stats in sorted(type_stats.items()):
acc = stats["correct"] / stats["total"] * 100
print(f" {step_type:<20} {acc:5.1f}% ({stats['correct']}/{stats['total']})")Encontrando pontos comuns de falha
import json
from collections import Counter
with open("training_data/prm_labels.jsonl") as f:
traces = [json.loads(line) for line in f]
# Analyze where errors first occur
error_positions = []
error_types_at_first_error = Counter()
for trace in traces:
if trace["first_error_step"] is not None:
pos = trace["first_error_step"]
total = trace["total_steps"]
# Normalize position to 0-1 range
error_positions.append(pos / total)
# Track what type of step caused the first error
error_step = trace["steps"][pos]
error_types_at_first_error[error_step["type"]] += 1
if error_positions:
avg_pos = sum(error_positions) / len(error_positions)
print(f"Average first-error position: {avg_pos:.2f} (0=start, 1=end)")
print(f"Traces with errors: {len(error_positions)}/{len(traces)}")
print()
print("Most common step types at first error:")
for step_type, count in error_types_at_first_error.most_common(5):
print(f" {step_type}: {count}")Calculando a concordância entre anotadores nos rótulos de PRM
import json
import numpy as np
from sklearn.metrics import cohen_kappa_score
def load_annotations(annotator_file):
"""Load annotations from a single annotator's output file."""
with open(annotator_file) as f:
data = {item["trace_id"]: item for item in
(json.loads(line) for line in f)}
return data
ann1 = load_annotations("output/reviewer1/annotations.jsonl")
ann2 = load_annotations("output/reviewer2/annotations.jsonl")
# Find overlapping traces
overlap_ids = set(ann1.keys()) & set(ann2.keys())
print(f"Overlapping traces: {len(overlap_ids)}")
# Compare first-error step labels
labels1 = []
labels2 = []
for trace_id in overlap_ids:
fe1 = ann1[trace_id].get("first_error_step", -1)
fe2 = ann2[trace_id].get("first_error_step", -1)
# Bin into: all_correct, early_error (first half), late_error (second half)
total = ann1[trace_id]["total_steps"]
for fe, labels in [(fe1, labels1), (fe2, labels2)]:
if fe is None or fe == -1:
labels.append("all_correct")
elif fe < total / 2:
labels.append("early_error")
else:
labels.append("late_error")
kappa = cohen_kappa_score(labels1, labels2)
print(f"Cohen's kappa (binned first-error): {kappa:.3f}")Dicas para coleta eficiente de dados de PRM
Use o modo primeiro-erro pela velocidade. Se você está treinando um PRM para guiar a busca (MCTS, amostragem best-of-N), o modo primeiro-erro te dá sinal suficiente a 2-3x a velocidade de anotação do modo por etapa. A maioria dos agentes falha em cascata de qualquer forma: um erro leva a uma cadeia de etapas ruins.
Use o modo por etapa quando você precisar do detalhe. Se você se importa com recuperação parcial, desvios inofensivos, ou está construindo um modelo de recompensa por etapa com mais de dois rótulos, o modo por etapa justifica o tempo extra.
Combine PRM com comparação pareada. Rotule os traces individualmente com PRM e depois rode uma comparação pareada nos traces que tentaram o mesmo problema. Uma passada de anotação te dá tanto recompensas por etapa quanto pares de preferência.
Comece com anotadores experientes. A anotação de PRM significa ler código, diffs e saída de terminal. Comece com um pequeno grupo de desenvolvedores experientes, meça a concordância, calibre contra exemplos e depois escale.
Defina um tempo mínimo por instância. Os traces ficam complicados. Um piso de 30 segundos impede que os anotadores passem correndo sem de fato ler as mudanças. Ajuste-o ao comprimento médio dos seus traces.
Forneça exemplos de calibração. Antes da anotação em produção, peça que todos rotulem os mesmos 10-20 traces e conversem sobre onde discordaram. Isso faz uma grande diferença na consistência.