Comparando Agentes de IA Lado a Lado: Modos Binário, de Escala e Multidimensional
Configure a comparação de agentes aos pares no Potato com três modos: preferência binária, escala contínua e julgamento multicritério por dimensão com justificativa obrigatória.
Por que comparação aos pares para avaliação de agentes
Pedir a alguém que avalie o trace de um agente de programação em uma escala de 1 a 10 gera dados ruidosos, porque cada pessoa calibra essa escala de um jeito. O 7 de um anotador é o 5 de outro. A comparação aos pares contorna isso. Em vez de avaliar traces isoladamente, os anotadores olham dois lado a lado e dizem qual é melhor. Esse tipo de julgamento direto é mais fácil de fazer, mais consistente entre pessoas e, por acaso, é exatamente o que você precisa para Direct Preference Optimization (DPO) e Reinforcement Learning from Human Feedback (RLHF).
É a mesma abordagem usada para treinar modelos de recompensa no alinhamento de modelos de linguagem, e ela se transfere com facilidade para agentes de programação: colete preferências humanas entre pares de trajetórias de agentes, treine um modelo de recompensa com elas e use esse modelo para guiar o treinamento do agente ou escolher o melhor dentre N candidatos na inferência.
O Potato tem três modos de comparação aos pares, cada um adequado a uma necessidade de avaliação e a um orçamento de dados diferente.
A interface coloca dois traces lado a lado:
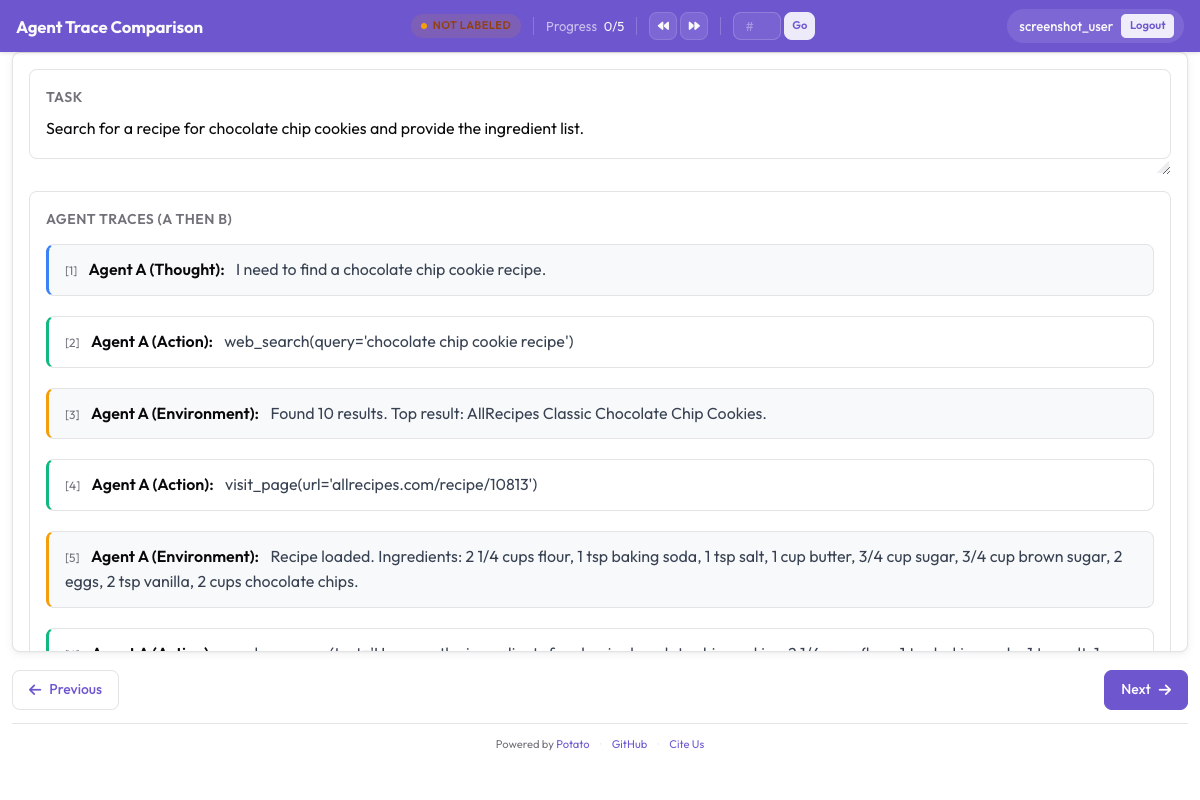 Annotators compare two agent traces and select which approach was better
Annotators compare two agent traces and select which approach was better
Modo 1: preferência binária
Este é o modo mais simples e rápido. O anotador vê dois traces lado a lado e clica no melhor. Um botão de empate opcional cobre os casos em que ambos são igualmente bons ou igualmente ruins.
Quando usar o modo binário
Recorra ao modo binário quando precisar de muitos dados de preferência rapidamente. Ele se encaixa bem para treinar modelos de recompensa básicos, calcular taxas de vitória de agentes e construir leaderboards de Elo. A desvantagem é que você perde a nuance. Você fica sabendo qual trace venceu, mas não por quanto nem em quais aspectos.
Configuração
# config.yaml
project_name: "Agent Comparison - Binary"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
position: "left"
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side" # "side_by_side" or "tabbed"
label_a: "Agent A"
label_b: "Agent B"
randomize_order: true # Randomize which trace appears on which side
show_agent_identity: false # Hide agent names to avoid bias
sync_scroll: false # Independent scrolling for each trace
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference
mode: "binary"
question: "Which agent produced a better solution?"
options:
- value: "a"
text: "Agent A is better"
keyboard_shortcut: "1"
- value: "b"
text: "Agent B is better"
keyboard_shortcut: "2"
- value: "tie"
text: "Tie (equally good or equally bad)"
keyboard_shortcut: "3"
allow_tie: true
require_justification: false # No text explanation needed
- annotation_type: radio
name: confidence
label: "How confident are you?"
options:
- value: "high"
text: "Very confident"
- value: "medium"
text: "Somewhat confident"
- value: "low"
text: "Not confident"
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 20
attention_checks:
enabled: true
frequency: 10 # Insert a check every 10 instances
type: "duplicate_reversed" # Re-show a pair with A/B swapped
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"O fluxo de anotação
O anotador recebe uma tela dividida. À esquerda, o Trace A é renderizado com o CodingTraceDisplay completo: diffs, blocos de terminal, leituras de arquivo, raciocínio. À direita, o Trace B para a mesma tarefa. Cada lado rola por conta própria.
A descrição da tarefa fica acima dos dois traces para que o anotador saiba o que os dois agentes estavam tentando fazer.
Abaixo deles há três botões: "Agent A is better", "Agent B is better" e "Tie." Com randomize_order ativado, qual agente é A e qual é B é embaralhado a cada instância, de modo que os anotadores não caiam em um hábito de lado esquerdo ou direito.
Para uma avaliação mais detalhada, a interface também suporta múltiplas dimensões:
 Binary preference, continuous scale, and multi-dimension modes are available
Binary preference, continuous scale, and multi-dimension modes are available
Modo 2: escala contínua
O modo de escala permite que o anotador diga o quanto um trace é melhor, não apenas qual venceu. Em vez de um único clique, ele arrasta um controle deslizante que vai de "A muito melhor" à esquerda até "B muito melhor" à direita, com "Igual" no meio.
Quando usar o modo de escala
Use o modo de escala quando a intensidade de uma preferência importa, não só a sua direção. Um deslizante próximo do extremo indica uma diferença clara de qualidade; próximo do centro indica que os dois ficaram empatados. O DPO e pipelines semelhantes podem ponderar os exemplos por essa intensidade, dando mais peso às decisões inequívocas.
Configuração
# config.yaml
project_name: "Agent Comparison - Scale"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side"
randomize_order: true
show_agent_identity: false
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference_scale
mode: "scale"
question: "Which agent produced a better solution, and by how much?"
scale:
points: 7 # 7-point scale
labels:
1: "A is much better"
2: "A is better"
3: "A is slightly better"
4: "Equal"
5: "B is slightly better"
6: "B is better"
7: "B is much better"
default: 4 # Start at "Equal"
show_numeric_value: true
require_justification: true
justification_label: "Briefly explain your rating"
justification_min_length: 20
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 20
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"Usando uma escala de 5 pontos
Para uma anotação mais rápida e um pouco menos de granularidade, reduza para uma escala de 5 pontos:
annotation_schemes:
- annotation_type: pairwise_comparison
name: preference_scale_5
mode: "scale"
question: "Compare the two solutions"
scale:
points: 5
labels:
1: "A is clearly better"
2: "A is somewhat better"
3: "About equal"
4: "B is somewhat better"
5: "B is clearly better"
default: 3Modo 3: comparação multidimensional
Este é o modo mais detalhado. Em vez de uma única preferência geral, o anotador julga cada trace em várias dimensões independentes. Cada dimensão recebe sua própria decisão A/B/Empate, e cada decisão precisa de uma justificativa escrita.
Quando usar o modo multidimensional
Use isto quando você quer saber não apenas qual agente venceu, mas por quê. Um trace pode ter código correto e eficiência péssima; outro pode ser eficiente, mas deixar passar um caso extremo. Os dados por dimensão que saem disso podem treinar modelos de recompensa específicos por dimensão ou fornecer notas detalhadas de volta às pessoas que constroem o agente.
Configuração
# config.yaml
project_name: "Agent Comparison - Multi-Dimension"
port: 8000
data:
source: "local"
input_path: "./data/paired_traces.jsonl"
data_format: "paired_coding_trace"
coding_agent:
display:
diff_style: "unified"
syntax_highlighting: true
terminal_theme: "dark"
file_tree:
enabled: true
collapsible:
auto_collapse_thinking: true
comparison:
layout: "side_by_side"
randomize_order: true
show_agent_identity: false
annotation_schemes:
- annotation_type: pairwise_comparison
name: multi_dim_comparison
mode: "multi_dimension"
question: "Compare the two solutions along each dimension"
dimensions:
- name: "correctness"
label: "Correctness"
description: >
Does the solution correctly fix the issue? Are there remaining
bugs, missed edge cases, or incorrect logic?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Why is this solution more correct?"
weight: 0.4 # Weight for computing overall preference
- name: "efficiency"
label: "Efficiency"
description: >
How efficient is the agent's process? Does it take unnecessary
steps, read irrelevant files, or make redundant edits?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which agent was more efficient and why?"
weight: 0.2
- name: "code_quality"
label: "Code Quality"
description: >
Is the code well-written? Consider readability, naming,
error handling, documentation, and adherence to existing patterns.
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which produces better quality code?"
weight: 0.2
- name: "communication"
label: "Communication"
description: >
How well does the agent explain its reasoning? Are its thinking
steps clear and logical? Does it identify the root cause?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which agent communicates its approach better?"
weight: 0.1
- name: "robustness"
label: "Robustness"
description: >
Does the solution handle edge cases? Does the agent verify its
changes with tests? Is the fix narrow and targeted or fragile?
options: ["A", "B", "Tie"]
require_justification: true
justification_placeholder: "Which solution is more robust?"
weight: 0.1
overall_preference:
enabled: true # Also ask for overall preference
question: "Overall, which solution do you prefer?"
options: ["A", "B", "Tie"]
require_justification: true
output:
path: "./output/"
format: "jsonl"
quality_control:
inter_annotator_agreement: true
overlap_percentage: 25 # Higher overlap for this detailed task
minimum_time_per_instance: 120 # 2 minutes minimum for thorough review
annotators:
- username: "judge1"
password: "judge_pw_1"
- username: "judge2"
password: "judge_pw_2"Preparando dados de traces pareados
Os três modos recebem traces pareados como entrada. Cada linha do arquivo JSONL contém dois traces que tentaram a mesma tarefa.
Formato dos dados
{
"id": "pair_001",
"task_description": "Fix the IndexError in process_batch() when the input list is empty",
"repo": "myorg/myproject",
"trace_a": {
"agent": "claude_code",
"model": "claude-sonnet-4-20250514",
"structured_turns": [
{
"step_idx": 0,
"type": "file_read",
"path": "src/batch.py",
"content": "def process_batch(items):\n result = items[0]\n ...",
"start_line": 10,
"end_line": 25
},
{
"step_idx": 1,
"type": "file_edit",
"path": "src/batch.py",
"diff": "--- a/src/batch.py\n+++ b/src/batch.py\n@@ -10,3 +10,5 @@\n def process_batch(items):\n+ if not items:\n+ return []\n result = items[0]\n"
},
{
"step_idx": 2,
"type": "bash_command",
"command": "python -m pytest tests/test_batch.py -v",
"output": "PASSED",
"exit_code": 0
}
]
},
"trace_b": {
"agent": "swe_agent",
"model": "gpt-4o",
"structured_turns": [
{
"step_idx": 0,
"type": "bash_command",
"command": "find . -name '*.py' | xargs grep 'process_batch'",
"output": "src/batch.py:def process_batch(items):\ntests/test_batch.py: process_batch([])",
"exit_code": 0
},
{
"step_idx": 1,
"type": "file_read",
"path": "src/batch.py",
"content": "def process_batch(items):\n result = items[0]\n ...",
"start_line": 1,
"end_line": 50
},
{
"step_idx": 2,
"type": "file_edit",
"path": "src/batch.py",
"diff": "--- a/src/batch.py\n+++ b/src/batch.py\n@@ -10,3 +10,6 @@\n def process_batch(items):\n+ if items is None or len(items) == 0:\n+ logger.warning('Empty input to process_batch')\n+ return []\n result = items[0]\n"
},
{
"step_idx": 3,
"type": "bash_command",
"command": "python -m pytest tests/ -v",
"output": "PASSED (12 tests)",
"exit_code": 0
}
]
}
}Construindo pares a partir de traces individuais
Se você tem traces individuais que abordaram as mesmas tarefas, o utilitário de pareamento vai montá-los:
# Generate all possible pairs for each task
potato pair-traces \
--input ./data/individual_traces.jsonl \
--output ./data/paired_traces.jsonl \
--pair_by "task_id" \
--strategy "all_pairs"
# Or sample a fixed number of pairs per task
potato pair-traces \
--input ./data/individual_traces.jsonl \
--output ./data/paired_traces.jsonl \
--pair_by "task_id" \
--strategy "sample" \
--pairs_per_task 3Exportando dados de comparação
Pares de preferência para DPO/RLHF
O principal formato de exportação para comparações aos pares são os pares de preferência para treinamento DPO ou RLHF:
potato export \
--format dpo_preferences \
--project ./output/ \
--output ./training_data/preferences.jsonlPara o modo binário, a saída é simples:
{
"prompt": "Fix the IndexError in process_batch() when the input list is empty",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001", "steps": [...]},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001", "steps": [...]},
"annotator": "judge1",
"confidence": "high"
}O modo de escala acrescenta a intensidade da preferência:
{
"prompt": "Fix the IndexError in process_batch()",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001"},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001"},
"preference_strength": 0.83,
"scale_value": 2,
"justification": "Agent A found and fixed the bug in fewer steps with cleaner code"
}O modo multidimensional carrega as preferências por dimensão:
{
"prompt": "Fix the IndexError in process_batch()",
"chosen": {"agent": "claude_code", "trace_id": "trace_a_001"},
"rejected": {"agent": "swe_agent", "trace_id": "trace_b_001"},
"overall_preference": "A",
"dimensions": {
"correctness": {"preference": "Tie", "justification": "Both correctly fix the bug"},
"efficiency": {"preference": "A", "justification": "A solves it in 3 steps vs 4"},
"code_quality": {"preference": "B", "justification": "B adds logging and handles None"},
"communication": {"preference": "A", "justification": "A's reasoning is more focused"},
"robustness": {"preference": "B", "justification": "B runs full test suite, not just one file"}
},
"weighted_score_a": 0.55,
"weighted_score_b": 0.45
}Análise: taxas de vitória, ratings de Elo e desdobramentos por dimensão
Calculando taxas de vitória
import json
from collections import defaultdict
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
wins = defaultdict(lambda: {"wins": 0, "losses": 0, "ties": 0})
for pref in prefs:
agent_chosen = pref["chosen"]["agent"]
agent_rejected = pref["rejected"]["agent"]
if agent_chosen == agent_rejected:
continue # Skip self-comparisons
if pref.get("overall_preference") == "Tie":
wins[agent_chosen]["ties"] += 1
wins[agent_rejected]["ties"] += 1
else:
wins[agent_chosen]["wins"] += 1
wins[agent_rejected]["losses"] += 1
print("Agent Win Rates:")
print("-" * 55)
for agent, record in sorted(wins.items()):
total = record["wins"] + record["losses"] + record["ties"]
win_rate = (record["wins"] + 0.5 * record["ties"]) / total * 100
print(f" {agent:<20} {win_rate:5.1f}% "
f"(W:{record['wins']} L:{record['losses']} T:{record['ties']})")Calculando ratings de Elo
import json
import math
from collections import defaultdict
def compute_elo(preferences, k=32, initial_rating=1500):
"""Compute Elo ratings from pairwise preferences."""
ratings = defaultdict(lambda: initial_rating)
for pref in preferences:
agent_a = pref["chosen"]["agent"]
agent_b = pref["rejected"]["agent"]
ra = ratings[agent_a]
rb = ratings[agent_b]
# Expected scores
ea = 1.0 / (1.0 + math.pow(10, (rb - ra) / 400))
eb = 1.0 / (1.0 + math.pow(10, (ra - rb) / 400))
overall = pref.get("overall_preference", "A")
if overall == "Tie":
sa, sb = 0.5, 0.5
else:
# "chosen" is the winner
sa, sb = 1.0, 0.0
ratings[agent_a] = ra + k * (sa - ea)
ratings[agent_b] = rb + k * (sb - eb)
return dict(ratings)
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
ratings = compute_elo(prefs)
print("Elo Ratings:")
print("-" * 35)
for agent, rating in sorted(ratings.items(), key=lambda x: -x[1]):
print(f" {agent:<20} {rating:.0f}")Desdobramentos por dimensão
Para comparações multidimensionais, observe em quais dimensões cada agente se sai bem:
import json
from collections import defaultdict
with open("training_data/preferences.jsonl") as f:
prefs = [json.loads(line) for line in f]
# Only process multi-dimension annotations
multi_dim = [p for p in prefs if "dimensions" in p]
dim_wins = defaultdict(lambda: defaultdict(lambda: {"A": 0, "B": 0, "Tie": 0}))
for pref in multi_dim:
agent_a = pref["chosen"]["agent"]
agent_b = pref["rejected"]["agent"]
pair_key = f"{agent_a} vs {agent_b}"
for dim_name, dim_data in pref["dimensions"].items():
dim_wins[dim_name][pair_key][dim_data["preference"]] += 1
print("Per-Dimension Win Rates:")
print("=" * 60)
for dim_name, matchups in sorted(dim_wins.items()):
print(f"\n {dim_name.upper()}")
print(f" {'-' * 50}")
for pair, counts in matchups.items():
total = counts["A"] + counts["B"] + counts["Tie"]
a_rate = (counts["A"] + 0.5 * counts["Tie"]) / total * 100
print(f" {pair}: A={a_rate:.0f}% B={100-a_rate:.0f}% "
f"(A:{counts['A']} B:{counts['B']} Tie:{counts['Tie']})")O que funciona na prática
Escolhendo um modo
O modo binário é a escolha certa quando você quer milhares de preferências rapidamente, um modelo de recompensa de uso geral ou uma classificação de leaderboard. Conte com cerca de 1 a 2 minutos por comparação.
O modo de escala vale a pena quando a intensidade da preferência alimenta seu pipeline de treinamento. O DPO com ponderação por margem se importa com a diferença entre uma preferência forte (deslizante no extremo) e uma fraca (deslizante perto do centro). Conte com 2 a 3 minutos por comparação.
O modo multidimensional compensa o tempo extra quando você precisa saber onde os agentes são fortes e fracos, quando está treinando modelos de recompensa específicos por dimensão ou quando deve aos desenvolvedores do agente um relatório detalhado. Conte com 4 a 6 minutos por comparação.
Quantas comparações você precisa
Para taxas de vitória confiáveis, colete pelo menos 100 comparações por par de agentes. Para ratings de Elo entre cinco ou mais agentes, de 200 a 300 comparações no total estabilizam as classificações. Para modelos de recompensa de DPO, mire em 1.000 ou mais pares de preferência que cubram tanto tarefas fáceis quanto difíceis.
Aleatorizando a ordem
Sempre defina randomize_order: true. O viés de posição, a tendência de preferir o trace que aparece à esquerda ou na primeira aba, está bem documentado em estudos de avaliação humana. Combine a aleatorização com a verificação attention_checks.type: "duplicate_reversed" para flagrar quem só fica clicando no mesmo lado.
Lidando com empates
No modo binário, permita empates, mas fique de olho na taxa de empate. Se ela passar de 30%, os agentes provavelmente estão próximos demais para uma decisão binária e você deve passar ao modo de escala ou multidimensional. No modo de escala, os empates são apenas o ponto central. No modo multidimensional, empates em dimensões individuais são esperados e dizem algo a você.
Ocultando a identidade do agente
Mantenha show_agent_identity: false a menos que tenha um motivo real para mostrá-la. Se os anotadores souberem qual agente produziu um trace, tendem a favorecer aquele que já esperam ser mais forte.
Combinando modos
Para uma avaliação completa, rode primeiro o modo binário sobre um grande conjunto de pares para obter classificações gerais, depois rode o modo multidimensional sobre um subconjunto menor e estratificado para o detalhe diagnóstico. As comparações binárias alimentam o treinamento do modelo de recompensa; as multidimensionais dizem onde focar as melhorias do agente.
Para a referência de configuração por trás desses modos, consulte a documentação de origem. Para um passo a passo mais amplo sobre como avaliar agentes de ponta a ponta, o guia de avaliação de agentes é o lugar para começar.