Avaliando Agentes de IA: Um Guia Completo para Anotação Humana de Traces de Agentes
Aprenda a configurar a avaliação humana de saídas de agentes de IA usando os recursos de anotação agêntica do Potato, da importação de traces ao design do esquema de anotação.
As métricas automáticas dizem com que frequência um agente tem sucesso. Elas não dizem por que ele falhou, que costuma ser justamente o que você precisa saber. A avaliação humana diz: ela mostra o passo em que o raciocínio saiu dos trilhos, não apenas a pontuação final. Este guia configura um pipeline completo de avaliação humana para agentes de IA usando os recursos de anotação agêntica do Potato.
 From raw traces to structured judgments
From raw traces to structured judgments
Vamos avaliar um agente no estilo ReAct que responde perguntas pesquisando na web. Ao final, você terá:
- Importado traces de agentes para o Potato
- Configurado a exibição de traces de agentes
- Definido esquemas de anotação tanto gerais quanto por passo
- Executado a tarefa de anotação
- Exportado resultados de avaliação estruturados
A exibição de traces de agentes do Potato renderiza cada passo com cartões codificados por cores para pensamentos, ações e observações:
Pré-requisitos
Instale o Potato 2.3.0 ou posterior:
pip install --upgrade potato-annotationVocê também precisará de traces de agentes para avaliar. Este guia usa traces ReAct, mas a mesma abordagem funciona para qualquer um dos 12 formatos suportados.
Passo 1: Prepare Seus Traces de Agentes
Um trace ReAct é uma sequência de passos de Thought, Action e Observation. Aqui está um exemplo mínimo. Crie um arquivo em data/traces.jsonl:
{
"trace_id": "trace_001",
"task": "What is the capital of Australia and what is its population?",
"trace": [
{"type": "thought", "content": "I need to find the capital of Australia and its population. Let me search for this."},
{"type": "action", "content": "search", "action_input": "capital of Australia"},
{"type": "observation", "content": "Canberra is the capital city of Australia. It was chosen as the capital in 1908 as a compromise between Sydney and Melbourne."},
{"type": "thought", "content": "The capital is Canberra. Now I need to find its population."},
{"type": "action", "content": "search", "action_input": "Canberra population 2025"},
{"type": "observation", "content": "Canberra has a population of approximately 467,000 as of 2025, making it the eighth-largest city in Australia."},
{"type": "thought", "content": "I now have both pieces of information. The capital of Australia is Canberra with a population of approximately 467,000."},
{"type": "action", "content": "finish", "action_input": "The capital of Australia is Canberra, with a population of approximately 467,000 as of 2025."}
],
"ground_truth": "Canberra, approximately 467,000"
}Cada linha do arquivo JSONL é um trace de agente completo. O campo trace contém o log passo a passo. O campo task é o que o agente foi solicitado a fazer.
Notas sobre o Formato dos Traces
Para traces de function-calling da OpenAI, o formato é diferente:
{
"trace_id": "oai_001",
"task": "Find cheap flights from NYC to London",
"messages": [
{"role": "user", "content": "Find cheap flights from NYC to London"},
{"role": "assistant", "content": null, "tool_calls": [{"function": {"name": "search_flights", "arguments": "{\"from\": \"NYC\", \"to\": \"LHR\"}"}}]},
{"role": "tool", "name": "search_flights", "content": "{\"flights\": [{\"airline\": \"BA\", \"price\": 450}, {\"airline\": \"AA\", \"price\": 520}]}"},
{"role": "assistant", "content": "I found flights from NYC to London. The cheapest is British Airways at $450."}
]
}O conversor do Potato lida com essas diferenças. Você só precisa especificar o nome correto do conversor.
Passo 2: Crie a Configuração do Projeto
Crie config.yaml:
annotation_task_name: "ReAct Agent Evaluation"
task_dir: "."
data_files:
- "data/traces.jsonl"
item_properties:
id_key: trace_id
text_key: task
# --- Agentic annotation settings ---
agentic:
enabled: true
trace_converter: react
display_type: agent_trace
agent_trace_display:
colors:
thought: "#6E56CF"
action: "#3b82f6"
observation: "#22c55e"
error: "#ef4444"
collapse_observations: true
collapse_threshold: 400
show_step_numbers: true
show_timestamps: false
render_json: true
syntax_highlight: trueIsso diz ao Potato para:
- Carregar traces de
data/traces.jsonl - Usar o conversor ReAct para fazer o parsing do campo
trace - Exibir traces usando a exibição de trace de agente com cartões de passo codificados por cores
Passo 3: Projete Seus Esquemas de Anotação
A avaliação de agentes normalmente precisa tanto de julgamentos a nível de trace (o agente teve sucesso?) quanto de julgamentos a nível de passo (cada passo estava correto?). Vamos adicionar ambos.
Adicione o seguinte ao config.yaml:
annotation_schemes:
# --- Trace-level schemas ---
# 1. Task success (the most important metric)
- annotation_type: radio
name: task_success
description: "Did the agent successfully complete the task?"
labels:
- "Success"
- "Partial Success"
- "Failure"
label_requirement:
required: true
sequential_key_binding: true
# 2. Answer correctness (if the task has a ground truth)
- annotation_type: radio
name: answer_correctness
description: "Is the agent's final answer factually correct?"
labels:
- "Correct"
- "Partially Correct"
- "Incorrect"
- "Cannot Determine"
label_requirement:
required: true
# 3. Efficiency rating
- annotation_type: likert
name: efficiency
description: "Did the agent use an efficient path to the answer?"
min: 1
max: 5
labels:
1: "Very Inefficient (many unnecessary steps)"
3: "Average"
5: "Optimal (no wasted steps)"
# 4. Free-text notes
- annotation_type: text
name: evaluator_notes
description: "Any additional observations"
label_requirement:
required: false
# --- Step-level schemas ---
# 5. Per-step correctness
- annotation_type: per_turn_rating
name: step_correctness
target: agentic_steps
description: "Was this step correct and useful?"
rating_type: radio
labels:
- "Correct"
- "Partially Correct"
- "Incorrect"
- "Unnecessary"
# 6. Per-step error type (only shown when step is not correct)
- annotation_type: per_turn_rating
name: error_type
target: agentic_steps
description: "What type of error occurred?"
rating_type: multiselect
labels:
- "Wrong tool/action"
- "Wrong arguments"
- "Hallucinated information"
- "Reasoning error"
- "Redundant step"
- "Premature termination"
- "Other"
conditional:
show_when:
step_correctness: ["Partially Correct", "Incorrect", "Unnecessary"]Isso cobre as duas pontas da análise. O rótulo de sucesso/falha e a avaliação de correção da resposta fornecem os números de alto nível. A pontuação de eficiência permite comparar estratégias. E as avaliações por passo, com uma taxonomia de erros que só aparece quando um passo é marcado como errado, dizem exatamente onde as coisas quebraram.
Passo 4: Configure a Saída e Inicie o Servidor
Adicione as configurações de saída ao config.yaml:
output_annotation_dir: "output/"
export_annotation_format: "jsonl"
# Optional: also export to Parquet for analysis
parquet_export:
enabled: true
output_dir: "output/parquet/"
compression: zstdconfig.yaml completo para referência:
annotation_task_name: "ReAct Agent Evaluation"
task_dir: "."
data_files:
- "data/traces.jsonl"
item_properties:
id_key: trace_id
text_key: task
agentic:
enabled: true
trace_converter: react
display_type: agent_trace
agent_trace_display:
colors:
thought: "#6E56CF"
action: "#3b82f6"
observation: "#22c55e"
error: "#ef4444"
collapse_observations: true
collapse_threshold: 400
show_step_numbers: true
render_json: true
syntax_highlight: true
annotation_schemes:
- annotation_type: radio
name: task_success
description: "Did the agent successfully complete the task?"
labels: ["Success", "Partial Success", "Failure"]
label_requirement:
required: true
sequential_key_binding: true
- annotation_type: radio
name: answer_correctness
description: "Is the agent's final answer factually correct?"
labels: ["Correct", "Partially Correct", "Incorrect", "Cannot Determine"]
label_requirement:
required: true
- annotation_type: likert
name: efficiency
description: "Did the agent use an efficient path?"
min: 1
max: 5
labels:
1: "Very Inefficient"
3: "Average"
5: "Optimal"
- annotation_type: text
name: evaluator_notes
description: "Any additional observations"
label_requirement:
required: false
- annotation_type: per_turn_rating
name: step_correctness
target: agentic_steps
description: "Was this step correct?"
rating_type: radio
labels: ["Correct", "Partially Correct", "Incorrect", "Unnecessary"]
- annotation_type: per_turn_rating
name: error_type
target: agentic_steps
description: "Error type"
rating_type: multiselect
labels:
- "Wrong tool/action"
- "Wrong arguments"
- "Hallucinated information"
- "Reasoning error"
- "Redundant step"
- "Premature termination"
- "Other"
conditional:
show_when:
step_correctness: ["Partially Correct", "Incorrect", "Unnecessary"]
output_annotation_dir: "output/"
export_annotation_format: "jsonl"
parquet_export:
enabled: true
output_dir: "output/parquet/"
compression: zstdInicie o servidor:
potato start config.yaml -p 8000Abra http://localhost:8000 no seu navegador.
Passo 5: O Fluxo de Trabalho de Anotação
Quando um anotador abre um trace, ele vê:
- Descrição da tarefa no topo (a consulta original do usuário)
- Cartões de passo mostrando o trace completo do agente, codificados por cores por tipo:
- Cartões roxos para pensamentos/raciocínio
- Cartões azuis para ações/chamadas de ferramenta
- Cartões verdes para observações/resultados
- Cartões vermelhos para erros
- Controles de avaliação por passo ao lado de cada cartão de passo
- Esquemas a nível de trace abaixo da exibição do trace
O fluxo de trabalho típico:
- Leia a descrição da tarefa para entender o que o agente deveria fazer
- Percorra os passos do trace, avaliando cada um
- Para qualquer passo avaliado como "Partially Correct" ou "Incorrect", selecione o(s) tipo(s) de erro
- Avalie o trace geral (sucesso, correção, eficiência)
- Adicione notas se necessário
- Envie e passe para o próximo trace
Dicas para anotadores
Expanda as observações recolhidas em vez de confiar nelas à primeira vista; é aí que você pega o agente interpretando errado o que encontrou. Compare a resposta final com o ground truth, se você tiver um, antes de avaliar o sucesso da tarefa. Mantenha "Unnecessary" e "Incorrect" separados, já que um passo desperdiçado custa esforço mas não introduz de fato um erro. E em traces longos, a barra lateral com a linha do tempo dos passos permite pular direto para o passo que importa.
Passo 6: Analisando os Resultados
Após a anotação, analise os resultados de forma programática.
Análise Básica com pandas
import pandas as pd
import json
# Load annotations
annotations = []
with open("output/annotations.jsonl") as f:
for line in f:
annotations.append(json.loads(line))
df = pd.DataFrame(annotations)
# Task success rate
success_counts = df.groupby("annotations").apply(
lambda x: x.iloc[0]["annotations"]["task_success"]
).value_counts()
print("Task Success Distribution:")
print(success_counts)
# Average efficiency rating
efficiency_scores = [
a["annotations"]["efficiency"]
for a in annotations
if "efficiency" in a["annotations"]
]
print(f"\nAverage Efficiency: {sum(efficiency_scores) / len(efficiency_scores):.2f}")Análise de Erros a Nível de Passo
# Collect all step-level errors
error_counts = {}
for ann in annotations:
step_errors = ann["annotations"].get("error_type", {})
for step_idx, errors in step_errors.items():
for error in errors:
error_counts[error] = error_counts.get(error, 0) + 1
print("Error Type Distribution:")
for error, count in sorted(error_counts.items(), key=lambda x: -x[1]):
print(f" {error}: {count}")Análise com DuckDB (via Parquet)
import duckdb
# Overall success rate
result = duckdb.sql("""
SELECT value, COUNT(*) as count
FROM 'output/parquet/annotations.parquet'
WHERE schema_name = 'task_success'
GROUP BY value
ORDER BY count DESC
""")
print(result)Passo 7: Escalando
Para projetos de avaliação maiores (centenas ou milhares de traces), considere estas configurações:
Múltiplos Anotadores
Atribua múltiplos anotadores por trace para concordância entre anotadores:
annotation_task_config:
total_annotations_per_instance: 3
assignment_strategy: randomUsando Esquemas Pré-Construídos
Para uma configuração rápida, use os esquemas de avaliação de agentes pré-construídos do Potato:
annotation_schemes:
- preset: agent_task_success
- preset: agent_step_correctness
- preset: agent_error_taxonomy
- preset: agent_efficiencyControle de Qualidade
Habilite instâncias de padrão-ouro para monitoramento de qualidade:
phases:
training:
enabled: true
data_file: "data/training_traces.jsonl"
passing_criteria:
min_correct: 4
total_questions: 5Adaptando para Outros Tipos de Agente
Function Calling da OpenAI
agentic:
enabled: true
trace_converter: openai
display_type: agent_traceUso de Ferramentas da Anthropic
agentic:
enabled: true
trace_converter: anthropic
display_type: agent_traceSistemas Multiagente (CrewAI/AutoGen)
agentic:
enabled: true
trace_converter: multi_agent
display_type: agent_trace
multi_agent:
agent_converters:
researcher: react
writer: anthropic
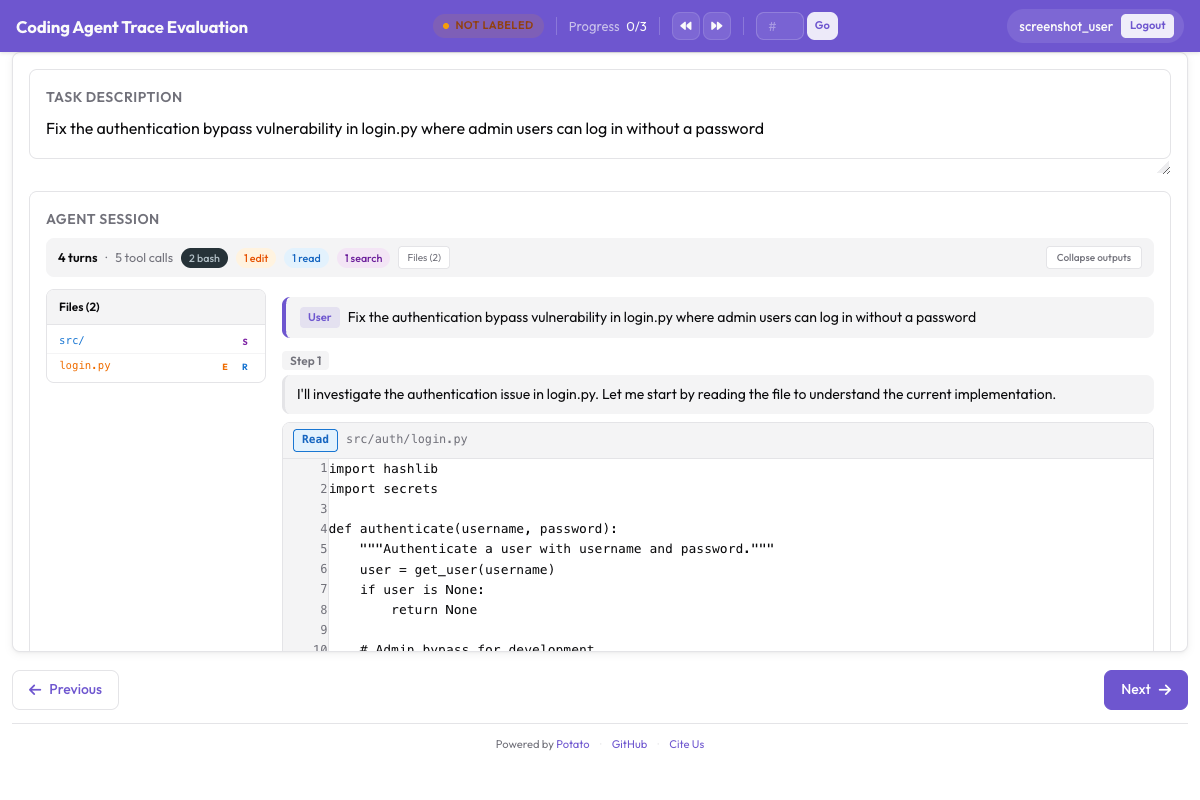
reviewer: openaiPara agentes de programação, o Potato renderiza diffs de código e saída de terminal com formatação adequada:
Agentes de Navegação Web
Para agentes web, mude para a exibição de agente web:
agentic:
enabled: true
trace_converter: webarena
display_type: web_agent
web_agent_display:
screenshot_max_width: 900
overlay:
enabled: true
filmstrip:
enabled: trueVeja Anotando Agentes de Navegação Web para um guia dedicado.
Resumo
Avaliar agentes manualmente exige as ferramentas certas, e o sistema de anotação agêntica do Potato foi feito para isso. Ele vem com 12 conversores de traces, então você consegue trazer traces da maioria dos frameworks sem reformatá-los, três tipos de exibição ajustados para uso de ferramentas, navegação web e agentes conversacionais, avaliações por turno para julgamentos a nível de passo, 9 esquemas pré-construídos para as dimensões de avaliação comuns, e exportação para Parquet para quando você sentar para analisar tudo.
O que vale lembrar: "o agente chegou à resposta certa?" é a pergunta fácil. A mais difícil é se ele raciocinou corretamente em cada passo, e essa é a que a anotação por passo responde. As métricas agregadas silenciosamente diluem esses erros na média.
Para detalhes de implementação, veja o guia de avaliação de agentes e a documentação de traces de agentes.
Leitura Adicional
- Documentação de Anotação Agêntica
- Anotando Agentes de Navegação Web
- Modo Solo -- combine anotação agêntica com avaliação colaborativa humano-LLM
- Best-Worst Scaling -- classifique saídas de agentes comparativamente
- Exportação para Parquet -- exportação eficiente para análise