Revisão de Código no Estilo de PR do GitHub para Agentes de Programação de IA
Configure a anotação de revisão de código no estilo de PR do GitHub no Potato com comentários inline em diffs, avaliações de qualidade por arquivo e veredictos de aprovar ou rejeitar para a saída de agentes de programação.
Por que a Anotação de Revisão de Código Importa
A maioria dos benchmarks de agentes de programação reduz a avaliação a um binário: os testes passaram ou não? O SWE-bench reporta uma porcentagem de issues resolvidas. O HumanEval reporta pass@k. Essas métricas são úteis para rankings, mas inúteis para entender a qualidade do código.
Um agente pode passar em todos os testes e ainda assim escrever código que ninguém gostaria de manter, código com uma brecha de segurança, um caminho lento ou um estilo que briga com o resto da base de código. Um revisor humano solicitaria mudanças nesse PR mesmo com os testes verdes. Se você quer agentes que escrevam código que as pessoas realmente fazem merge, você precisa revisar o código, não apenas rodar os testes.
O schema de anotação code_review do Potato traz a experiência de revisão de PR do GitHub para dentro de uma ferramenta de anotação. Os anotadores veem diffs unificados com realce de sintaxe, clicam em linhas do diff para adicionar comentários inline, avaliam arquivos em algumas dimensões de qualidade e dão um veredicto de aprovar, solicitar mudanças ou apenas comentar, igual à revisão de um pull request real. Para a referência completa do schema, consulte a documentação de anotação de agentes de programação e o guia de avaliação de agentes.
Aqui está a interface de revisão de código no Potato, mostrando comentários inline em diffs e avaliações por arquivo:
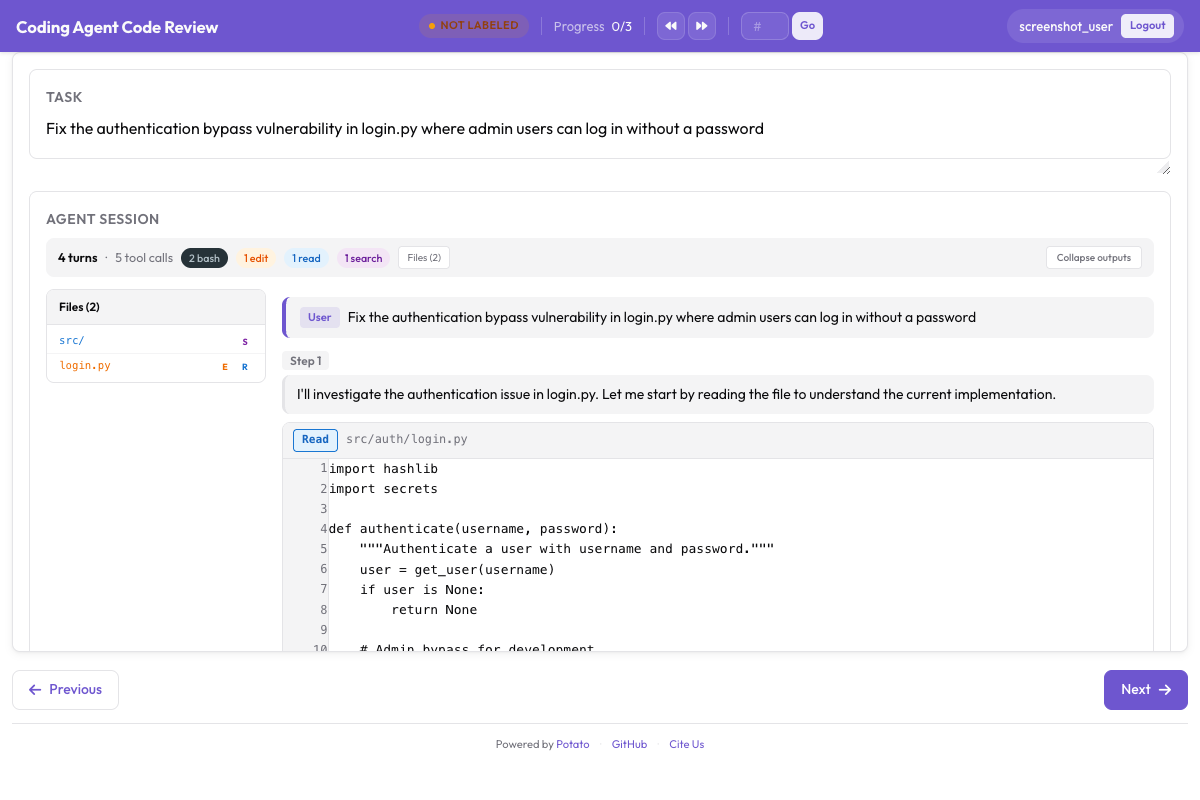 Interface de revisão de código do Potato com comentários inline em diffs e avaliações de qualidade por arquivo
Interface de revisão de código do Potato com comentários inline em diffs e avaliações de qualidade por arquivo
Visão Geral do Schema de Revisão de Código
O schema code_review tem três camadas:
- Comentários inline em diffs: os anotadores clicam em qualquer linha do diff para anexar um comentário categorizado (bug, estilo, desempenho, segurança, lógica, sugestão, pergunta)
- Avaliações por arquivo: cada arquivo modificado recebe avaliações independentes de correção (1-5) e qualidade de código (1-5)
- Veredicto geral: o anotador emite um veredicto final: aprovar, solicitar mudanças ou apenas comentar
Isso espelha uma revisão de código real, então parece natural para desenvolvedores, e a saída estruturada que ele produz mapeia diretamente para o treinamento de modelos de revisão de código.
CodingTraceDisplay: Como os Diffs São Renderizados
O componente CodingTraceDisplay renderiza traces de agentes de programação como uma sequência de chamadas de ferramentas e suas saídas, com tratamento especial para edições de arquivos. Quando o agente edita um arquivo, a exibição mostra um diff unificado com:
- Linhas vermelhas: linhas deletadas (prefixadas com
-) - Linhas verdes: linhas adicionadas (prefixadas com
+) - Linhas cinza: linhas de contexto (inalteradas)
- Números de linha: números de linha antigos e novos na margem
- Realce de sintaxe: realce ciente da linguagem com base na extensão do arquivo
- Clique para comentar: clicar em qualquer linha abre um formulário de comentário ancorado àquela linha
O diff é calculado automaticamente a partir das operações de edição do agente. Se o agente usou uma ferramenta de busca e substituição, o Potato reconstrói os estados antes/depois e gera o diff unificado.
Para agentes que produzem múltiplas edições de arquivo em um único trace (comum em correções de bugs do mundo real), cada arquivo recebe sua própria seção de diff recolhível, semelhante à aba "Files changed" do PR do GitHub.
O CodingTraceDisplay renderiza as mudanças de código com realce de sintaxe adequado:
 CodingTraceDisplay renderizando diffs unificados com realce de sintaxe e uma barra lateral de árvore de arquivos
CodingTraceDisplay renderizando diffs unificados com realce de sintaxe e uma barra lateral de árvore de arquivos
Categorias de Comentários
Quando um anotador clica em uma linha do diff para adicionar um comentário, ele seleciona uma categoria:
| Categoria | Cor | Descrição | Exemplo |
|---|---|---|---|
bug | Vermelho | O código tem um erro funcional | "Isso vai lançar um NullPointerException se user for None" |
style | Azul | Problema de estilo ou convenção de código | "O projeto usa snake_case para funções, não camelCase" |
performance | Laranja | Código ineficiente | "Isso consulta o banco de dados dentro de um loop; use uma consulta em lote" |
security | Roxo | Vulnerabilidade de segurança | "A entrada do usuário é passada diretamente para a consulta SQL sem sanitização" |
logic | Amarelo | Problema de lógica que pode não causar falha imediata | "Esta condição deveria ser >= e não >, erro de um a mais no limite" |
suggestion | Verde | Sugestão de melhoria, não um erro | "Considere usar um context manager aqui para um gerenciamento de recursos mais limpo" |
question | Cinza | Esclarecimento necessário | "Por que este import foi adicionado? Ele não parece ser usado" |
Cada comentário também tem um corpo de texto livre onde o anotador explica o problema em detalhe, assim como ao escrever um comentário de PR real.
Avaliações por Arquivo
Depois de revisar o diff de cada arquivo, o anotador o avalia em duas dimensões:
Correção (1-5):
- 1: não funciona, introduz novos bugs
- 2: funciona parcialmente, tem problemas significativos
- 3: funciona no caminho feliz, mas ignora casos extremos
- 4: funciona corretamente com problemas menores
- 5: totalmente correto, trata casos extremos apropriadamente
Qualidade de Código (1-5):
- 1: insustentável, sem estrutura
- 2: baixa qualidade, problemas significativos de estilo/design
- 3: aceitável, segue convenções básicas
- 4: boa qualidade, limpo e legível
- 5: excelente, idiomático, bem documentado
Opções de Veredicto
Depois de revisar todos os arquivos, o anotador seleciona um de três veredictos:
- Aprovar: o código está pronto para merge como está, ou apenas com mudanças triviais
- Solicitar Mudanças: o código precisa de revisões significativas antes do merge
- Apenas Comentar: fornecer feedback sem tomar uma decisão de merge
Isso mapeia diretamente para os três estados de revisão de PR do GitHub.
Configuração Passo a Passo
Passo 1: Converter Traces de Agentes de Programação
Os traces de agentes de programação vêm em muitos formatos. Aqui estão exemplos para três agentes populares.
Do Claude Code (exportação JSON):
python -m potato.convert_traces \
--input claude_code_sessions/ \
--output data/code_traces.jsonl \
--format claude_codeDo Aider (histórico de chat):
python -m potato.convert_traces \
--input aider_logs/ \
--output data/code_traces.jsonl \
--format aiderDo SWE-Agent (diretório de trajetórias):
python -m potato.convert_traces \
--input swe_agent_trajectories/ \
--output data/code_traces.jsonl \
--format swe_agentO conversor produz um formato JSONL padronizado. Cada linha contém um trace com a tarefa, os passos do agente e os diffs dos arquivos:
{
"trace_id": "swe_bench_123",
"task": "Fix the TypeError in django/db/models/query.py when calling .values() on an empty QuerySet",
"repo": "django/django",
"base_commit": "a1b2c3d",
"steps": [
{
"type": "thought",
"content": "Let me look at the QuerySet.values() method to understand the TypeError."
},
{
"type": "action",
"tool": "search",
"input": "def values",
"file": "django/db/models/query.py"
},
{
"type": "observation",
"content": "Found at line 234: def values(self, *fields):\n ..."
},
{
"type": "action",
"tool": "edit",
"file": "django/db/models/query.py",
"old_content": " def values(self, *fields):\n clone = self._clone()\n clone.query.set_values(fields)",
"new_content": " def values(self, *fields):\n clone = self._clone()\n if not fields and not self.query.values_select:\n return clone\n clone.query.set_values(fields)"
},
{
"type": "action",
"tool": "edit",
"file": "tests/queries/test_values.py",
"old_content": "class ValuesTests(TestCase):",
"new_content": "class ValuesTests(TestCase):\n def test_empty_queryset_values(self):\n \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n qs = Author.objects.none()\n result = list(qs.values())\n self.assertEqual(result, [])"
}
],
"files_changed": [
{
"path": "django/db/models/query.py",
"diff": "--- a/django/db/models/query.py\n+++ b/django/db/models/query.py\n@@ -234,6 +234,8 @@\n def values(self, *fields):\n clone = self._clone()\n+ if not fields and not self.query.values_select:\n+ return clone\n clone.query.set_values(fields)"
},
{
"path": "tests/queries/test_values.py",
"diff": "--- a/tests/queries/test_values.py\n+++ b/tests/queries/test_values.py\n@@ -1,4 +1,10 @@\n class ValuesTests(TestCase):\n+ def test_empty_queryset_values(self):\n+ \"\"\"Calling .values() on empty QuerySet should not raise TypeError.\"\"\"\n+ qs = Author.objects.none()\n+ result = list(qs.values())\n+ self.assertEqual(result, [])"
}
]
}Passo 2: Configurar o Schema de Revisão de Código
Crie seu config.yaml:
annotation_task_name: "Coding Agent Code Review"
data_files:
- "data/code_traces.jsonl"
item_properties:
id_key: "trace_id"
text_key: "task"
# Display coding agent traces with diff rendering
display:
type: "coding_trace"
trace_key: "steps"
diff_key: "files_changed"
syntax_highlighting: true
show_line_numbers: true
collapse_large_diffs: true
max_uncollapsed_lines: 200
annotation_schemes:
- annotation_type: "code_review"
name: "review"
description: "Review the agent's code changes as you would a GitHub PR"
# Inline comment categories
comment_categories:
- name: "bug"
label: "Bug"
color: "#DC2626"
description: "Functional error in the code"
- name: "style"
label: "Style"
color: "#2563EB"
description: "Code style or convention issue"
- name: "performance"
label: "Performance"
color: "#EA580C"
description: "Inefficient code or unnecessary computation"
- name: "security"
label: "Security"
color: "#9333EA"
description: "Security vulnerability or unsafe practice"
- name: "logic"
label: "Logic"
color: "#CA8A04"
description: "Logic issue that may not cause immediate failure"
- name: "suggestion"
label: "Suggestion"
color: "#16A34A"
description: "Improvement idea, not an error"
- name: "question"
label: "Question"
color: "#6B7280"
description: "Clarification needed"
# File-level ratings
file_ratings:
- name: "correctness"
label: "Correctness"
scale: 5
descriptions:
1: "Does not work, introduces new bugs"
2: "Partially works, has significant issues"
3: "Works for happy path, misses edge cases"
4: "Works correctly with minor issues"
5: "Fully correct, handles edge cases"
- name: "code_quality"
label: "Code Quality"
scale: 5
descriptions:
1: "Unmaintainable, no structure"
2: "Poor quality, significant style issues"
3: "Acceptable, follows basic conventions"
4: "Good quality, clean and readable"
5: "Excellent, idiomatic, well-documented"
# Overall verdict
verdict:
options:
- name: "approve"
label: "Approve"
color: "#16A34A"
description: "Ready to merge as-is or with trivial changes"
- name: "request_changes"
label: "Request Changes"
color: "#DC2626"
description: "Needs significant revisions before merging"
- name: "comment"
label: "Comment Only"
color: "#6B7280"
description: "Providing feedback without a merge decision"
# Annotator settings
annotator_config:
allow_back_navigation: true
# Output settings
output:
path: "output/"
format: "jsonl"Passo 3: Iniciar o Servidor de Anotação
potato start config.yaml -p 8000Navegue até http://localhost:8000. Você verá o primeiro trace de agente de programação com a descrição da tarefa, os passos de raciocínio do agente e os diffs dos arquivos renderizados com realce de sintaxe.
Passo 4: O Fluxo de Trabalho do Anotador
Aqui está o fluxo de revisão típico:
- Leia a tarefa: entenda o que o agente foi solicitado a fazer (por exemplo, "Fix the TypeError in django/db/models/query.py")
- Revise o trace: percorra os passos de raciocínio do agente para entender sua abordagem
- Revise o diff de cada arquivo:
- Leia o diff com realce de sintaxe
- Clique em qualquer linha para adicionar um comentário inline
- Selecione uma categoria de comentário (bug, estilo, desempenho, etc.)
- Escreva o corpo do comentário explicando o problema
- Avalie o arquivo em correção (1-5) e qualidade de código (1-5)
- Emita o veredicto: selecione aprovar, solicitar mudanças ou apenas comentar
- Envie: clique em "Submit" ou pressione Ctrl+Enter
Atalhos de teclado aceleram o fluxo de trabalho:
| Atalho | Ação |
|---|---|
j / k | Navegar entre arquivos |
c | Abrir comentário na linha selecionada |
1-5 | Definir avaliação para a dimensão atual |
a | Definir veredicto como aprovar |
r | Definir veredicto como solicitar mudanças |
Ctrl+Enter | Enviar revisão |
Formato de Exportação
Cada revisão enviada produz um objeto JSON estruturado:
{
"trace_id": "swe_bench_123",
"annotator": "reviewer_01",
"timestamp": "2026-03-22T14:32:11Z",
"review": {
"inline_comments": [
{
"file": "django/db/models/query.py",
"line": 236,
"side": "right",
"category": "logic",
"body": "This early return skips set_values entirely, but if fields are provided later via .values('name'), the previous empty .values() call will have returned a clone that never went through set_values. Consider checking if this clone is still valid downstream."
},
{
"file": "tests/queries/test_values.py",
"line": 5,
"side": "right",
"category": "suggestion",
"body": "Consider adding a test case for .values() followed by .values('name') to verify the chaining behavior after your fix."
}
],
"file_ratings": [
{
"file": "django/db/models/query.py",
"correctness": 3,
"code_quality": 4
},
{
"file": "tests/queries/test_values.py",
"correctness": 4,
"code_quality": 4
}
],
"verdict": "request_changes"
}
}Esse formato estruturado é diretamente utilizável para treinar modelos de revisão de código e para análise agregada.
Análise: Trabalhando com Dados de Revisão
Carregando Revisões
import json
import pandas as pd
from pathlib import Path
reviews = []
for f in Path("output/").glob("*.jsonl"):
with open(f) as fh:
for line in fh:
reviews.append(json.loads(line))
print(f"Loaded {len(reviews)} code reviews")Distribuição das Categorias de Comentários
from collections import Counter
all_comments = []
for rev in reviews:
for comment in rev["review"]["inline_comments"]:
all_comments.append(comment)
category_counts = Counter(c["category"] for c in all_comments)
print("Comment categories:")
for cat, count in category_counts.most_common():
print(f" {cat}: {count}")Avaliações Médias por Arquivo
ratings = []
for rev in reviews:
for fr in rev["review"]["file_ratings"]:
ratings.append(fr)
ratings_df = pd.DataFrame(ratings)
print("Average ratings by file:")
print(
ratings_df.groupby("file")[["correctness", "code_quality"]]
.mean()
.round(2)
.to_string()
)Distribuição dos Veredictos
verdict_counts = Counter(rev["review"]["verdict"] for rev in reviews)
total = sum(verdict_counts.values())
print("Verdict distribution:")
for verdict, count in verdict_counts.most_common():
print(f" {verdict}: {count} ({count/total*100:.1f}%)")Taxa de Bugs por Agente
Se seus traces incluem um campo agent, você pode comparar as taxas de bugs entre agentes:
agent_bugs = {}
for rev in reviews:
agent = rev.get("agent", "unknown")
bug_count = sum(
1 for c in rev["review"]["inline_comments"]
if c["category"] == "bug"
)
if agent not in agent_bugs:
agent_bugs[agent] = []
agent_bugs[agent].append(bug_count)
print("Average bugs per review by agent:")
for agent, bugs in sorted(agent_bugs.items()):
print(f" {agent}: {sum(bugs)/len(bugs):.2f} (n={len(bugs)})")Casos de Uso
Treinando Modelos de Revisão de Código
Os comentários inline estruturados, as avaliações de arquivo e os veredictos da anotação de revisão de código do Potato são dados de treinamento ideais para modelos automatizados de revisão de código. Cada revisão fornece:
- Feedback localizado vinculado a linhas específicas do diff
- Problemas categorizados (bug vs. estilo vs. desempenho)
- Sinais de qualidade em múltiplas granularidades (linha, arquivo, geral)
Esse é o formato de dados usado por ferramentas como CodeRabbit e o revisor de IA do Graphite, mas gerado por especialistas humanos em vez de destilado de um LLM.
Avaliando Agentes de Programação no SWE-bench
O SWE-bench diz se o agente resolveu a issue (os testes passam), mas não se o código pode ser mesclado. Ao rodar a anotação de revisão de código nas soluções do SWE-bench, você pode identificar agentes que resolvem issues com código limpo versus agentes que resolvem issues com gambiarras. Isso produz um ranking mais matizado que se correlaciona com a experiência real dos desenvolvedores.
Construindo Conjuntos de Dados de Qualidade de Código
Agregue dados de revisão de código de muitos traces para construir conjuntos de dados de problemas comuns de qualidade de código em código gerado por IA. Esses conjuntos de dados podem ser usados para:
- Fazer fine-tuning de modelos de geração de código para evitar erros comuns
- Construir linters específicos para padrões de código gerado por IA
- Treinar classificadores que sinalizam problemas prováveis na saída do agente antes da revisão humana
Resumo
O schema code_review do Potato coloca o fluxo de trabalho de revisão de PR do GitHub dentro da avaliação de agentes. Os comentários inline, as avaliações de arquivo e os veredictos que você coleta fornecem dados estruturados de qualidade de código, o que é muito mais do que um resultado de teste de passou/falhou revela. Esses são os dados de que você precisa, seja para treinar um modelo de revisão de código, separar soluções limpas do SWE-bench das cheias de gambiarras, ou apenas estabelecer uma linha de base de qualidade para o seu agente.