Per-Step Error Localization: Using Trajectory Evaluation to Find Where Agents Fail
Use Potato's trajectory_eval schema for per-step error localization with hierarchical error taxonomies, severity scoring, and running score tracking across agent traces.
The problem: knowing an agent failed is not enough
 A trajectory error taxonomy
A trajectory error taxonomy
You run your agent on a benchmark. It scores 63% on task completion. Now what?
A pass/fail number tells you the agent failed on 37% of tasks and nothing else. It doesn't tell you where in the trace things went wrong, what type of error the agent made, or how bad it was. Was it a single catastrophic mistake on step 2, or fifteen steps of minor reasoning errors piling up? Did the agent misuse a tool, or reason from a false premise?
Without per-step error localization, you can't diagnose failure modes, decide what to fix first, or build training data for process reward models. You're tuning hyperparameters in the dark.
Potato's trajectory_eval annotation schema fixes this. Annotators walk through each step of a trace and record:
- Correctness: Is this step correct or incorrect?
- Error type: Selected from a hierarchical taxonomy you define
- Severity level: Minor, major, or critical, with configurable score weights
- Rationale: Free-text explanation of the error (optional)
- Running score: A cumulative score that decrements based on severity, giving you a per-trace quality curve
This guide covers the full setup: defining your error taxonomy, running the annotation, and analyzing the collected data. For the schema's configuration reference, see the source documentation.
Trajectory eval schema overview
The trajectory_eval schema is built for evaluating multi-step agent traces in sequence. Instead of a single overall quality rating, it produces a structured error annotation for every step, so you end up with a detailed map of where and why the agent failed.
Here is what the annotation interface does at each step:
- The annotator sees the current step content (thought, action, observation, code, etc.)
- They mark the step as correct or incorrect
- If incorrect, they select an error type from the hierarchical taxonomy
- They assign a severity level (minor, major, or critical)
- Optionally, they write a rationale explaining the error
- The running score at the top of the interface updates automatically
The annotator moves through the trace one step at a time, building up a complete error profile.
The trajectory evaluation interface shows each step with its score:
 Each step gets a correctness rating, error type, and severity level with a running score that decrements based on severity
Each step gets a correctness rating, error type, and severity level with a running score that decrements based on severity
Designing a hierarchical error taxonomy
The taxonomy is what makes trajectory evaluation worth doing. Get it right and you can aggregate errors across traces and spot systematic failure patterns; get it wrong and your labels won't add up to anything. Here is a taxonomy I'd start from, with four top-level categories.
Reasoning errors
These happen when the agent's reasoning is flawed, even if what it sees and does is otherwise fine.
| Error Type | Description | Example |
|---|---|---|
logical_error | Invalid logical inference | "Since A implies B, and B is true, A must be true" (affirming the consequent) |
incorrect_assumption | Assumes something not supported by evidence | Assumes a file exists without checking |
over_generalization | Draws too broad a conclusion from limited evidence | "This function failed once, so the entire API is broken" |
circular_reasoning | Conclusion is used as a premise | "The answer is X because X is correct" |
incorrect_calculation | Mathematical or logical computation error | Off-by-one error in loop bound reasoning |
Perception errors
These happen when the agent misreads, misinterprets, or misses information in its observations.
| Error Type | Description | Example |
|---|---|---|
missed_element | Fails to notice relevant information | Overlooks an error message in terminal output |
misidentified_element | Misinterprets what it sees | Reads a 404 error as a successful response |
hallucinated_element | Refers to something not present | References a function parameter that does not exist |
outdated_reference | Uses stale information from a previous step | Uses a variable value that was overwritten |
Action errors
These happen when the agent takes the wrong action, or the right action the wrong way.
| Error Type | Description | Example |
|---|---|---|
wrong_tool | Selects an inappropriate tool for the task | Uses grep when find is needed |
wrong_arguments | Correct tool but incorrect parameters | Passes wrong file path to an edit command |
premature_termination | Stops before the task is complete | Returns an answer after finding partial information |
unnecessary_action | Takes an action that adds no value | Re-reads a file that was just read |
destructive_action | Takes an action that causes harm | Deletes a file without backup |
Communication errors
These show up in the agent's responses to users or in how it narrates its own work.
| Error Type | Description | Example |
|---|---|---|
unclear_explanation | Explanation is confusing or ambiguous | Describes a fix without saying what was broken |
missing_context | Omits critical context from response | Reports success without mentioning caveats |
incorrect_summary | Summary does not match actual actions | Claims to have edited 3 files when only 2 were changed |
overconfident_claim | States uncertainty as certainty | "This will definitely fix the issue" for an untested change |
Severity levels and score weights
Each error gets a severity level. The default weights are:
| Severity | Weight | Description |
|---|---|---|
minor | -1 | Small issues that do not derail the trace (e.g., unnecessary action, unclear explanation) |
major | -5 | Significant errors that waste effort or produce partially wrong results (e.g., wrong tool, incorrect assumption) |
critical | -10 | Errors that fundamentally break the trace (e.g., destructive action, premature termination with wrong answer) |
The running score starts at 100 and drops by the severity weight at each error. A trace that ends at 85 had a few minor issues; one that ends at 40 had several major failures.
You can change these weights in the configuration:
severity_levels:
- name: minor
weight: -1
description: "Small issue, does not derail the overall trace"
- name: major
weight: -5
description: "Significant error that wastes effort or produces wrong intermediate results"
- name: critical
weight: -10
description: "Fundamental failure that breaks the trace or causes harm"Full YAML configuration
Here is a complete config.yaml for trajectory evaluation with the full taxonomy:
annotation_task_name: "Agent Trajectory Error Localization"
data_files:
- "data/traces.jsonl"
item_properties:
id_key: "trace_id"
text_key: "task"
# Display agent traces with step-by-step rendering
display:
type: "agent_trace"
trace_key: "trace"
step_display:
thought: { label: "Thought", color: "#E8F0FE" }
action: { label: "Action", color: "#FFF3E0" }
observation: { label: "Observation", color: "#F1F8E9" }
code: { label: "Code", color: "#F3E5F5" }
annotation_schemes:
- annotation_type: "trajectory_eval"
name: "error_localization"
description: "Evaluate each step for correctness and classify any errors"
# Per-step correctness check
step_correctness:
labels: ["correct", "incorrect"]
default: "correct"
# Hierarchical error taxonomy (shown when step is marked incorrect)
error_taxonomy:
- category: "reasoning"
label: "Reasoning Error"
types:
- name: "logical_error"
label: "Logical Error"
description: "Invalid logical inference or deduction"
- name: "incorrect_assumption"
label: "Incorrect Assumption"
description: "Assumes something not supported by available evidence"
- name: "over_generalization"
label: "Over-generalization"
description: "Draws too broad a conclusion from limited evidence"
- name: "circular_reasoning"
label: "Circular Reasoning"
description: "Uses the conclusion as a premise"
- name: "incorrect_calculation"
label: "Incorrect Calculation"
description: "Mathematical or logical computation error"
- category: "perception"
label: "Perception Error"
types:
- name: "missed_element"
label: "Missed Element"
description: "Fails to notice relevant information in observations"
- name: "misidentified_element"
label: "Misidentified Element"
description: "Misinterprets what it observes"
- name: "hallucinated_element"
label: "Hallucinated Element"
description: "Refers to something not present in the context"
- name: "outdated_reference"
label: "Outdated Reference"
description: "Uses stale information from a previous step"
- category: "action"
label: "Action Error"
types:
- name: "wrong_tool"
label: "Wrong Tool"
description: "Selects an inappropriate tool for the task"
- name: "wrong_arguments"
label: "Wrong Arguments"
description: "Correct tool but incorrect parameters"
- name: "premature_termination"
label: "Premature Termination"
description: "Stops before the task is complete"
- name: "unnecessary_action"
label: "Unnecessary Action"
description: "Takes an action that adds no value"
- name: "destructive_action"
label: "Destructive Action"
description: "Takes an action that causes harm or data loss"
- category: "communication"
label: "Communication Error"
types:
- name: "unclear_explanation"
label: "Unclear Explanation"
description: "Explanation is confusing or ambiguous"
- name: "missing_context"
label: "Missing Context"
description: "Omits critical context from the response"
- name: "incorrect_summary"
label: "Incorrect Summary"
description: "Summary does not match the actual actions taken"
- name: "overconfident_claim"
label: "Overconfident Claim"
description: "States uncertain outcomes as certainties"
# Severity levels with score weights
severity_levels:
- name: "minor"
weight: -1
description: "Small issue, does not derail the overall trace"
- name: "major"
weight: -5
description: "Significant error that wastes effort or produces wrong results"
- name: "critical"
weight: -10
description: "Fundamental failure that breaks the trace or causes harm"
# Running score configuration
running_score:
initial: 100
min: 0
display: true
# Optional rationale field
rationale:
enabled: true
placeholder: "Explain why this step is incorrect..."
# Overall trace quality (optional, shown at the end)
- annotation_type: "radio"
name: "overall_success"
description: "Did the agent ultimately complete the task correctly?"
labels:
- name: "success"
tooltip: "Task completed correctly"
- name: "partial"
tooltip: "Task partially completed or completed with errors"
- name: "failure"
tooltip: "Task not completed or fundamentally wrong"
# Annotator settings
annotator_config:
allow_back_navigation: true
require_all_steps: true
# Output settings
output:
path: "output/"
format: "jsonl"Step-by-step setup
1. Prepare your agent traces
Trace data goes in JSONL format, one trace per line. Each trace needs an ID, a task description, and a list of steps:
{
"trace_id": "trace_042",
"task": "Find the bug in the calculate_discount function and fix it",
"trace": [
{
"type": "thought",
"content": "I need to look at the calculate_discount function to find the bug. Let me search for it."
},
{
"type": "action",
"content": "search",
"action_input": "def calculate_discount"
},
{
"type": "observation",
"content": "Found in pricing.py line 45:\ndef calculate_discount(price, discount_pct):\n return price * discount_pct / 100"
},
{
"type": "thought",
"content": "The function calculates the discount amount but doesn't subtract it from the price. It should return price - (price * discount_pct / 100)."
},
{
"type": "action",
"content": "edit_file",
"action_input": "pricing.py:45: return price - (price * discount_pct / 100)"
},
{
"type": "observation",
"content": "File edited successfully."
},
{
"type": "action",
"content": "finish",
"action_input": "Fixed the calculate_discount function. It was returning the discount amount instead of the discounted price."
}
]
}If your traces are in a different format (OpenAI messages, LangChain runs, Claude conversation logs), use the Potato trace converter:
python -m potato.convert_traces \
--input raw_traces/ \
--output data/traces.jsonl \
--format react2. Configure your taxonomy
Start with the full taxonomy above, then trim or extend it for your agent. For a coding agent, for instance, you might add a code_quality category:
- category: "code_quality"
label: "Code Quality Error"
types:
- name: "syntax_error"
label: "Syntax Error"
description: "Generated code has syntax errors"
- name: "runtime_error"
label: "Runtime Error"
description: "Code runs but produces an error"
- name: "logic_bug"
label: "Logic Bug"
description: "Code runs without errors but produces wrong output"
- name: "style_violation"
label: "Style Violation"
description: "Code works but violates project conventions"For coding agent traces, the evaluation renders diffs and terminal output alongside the scoring:
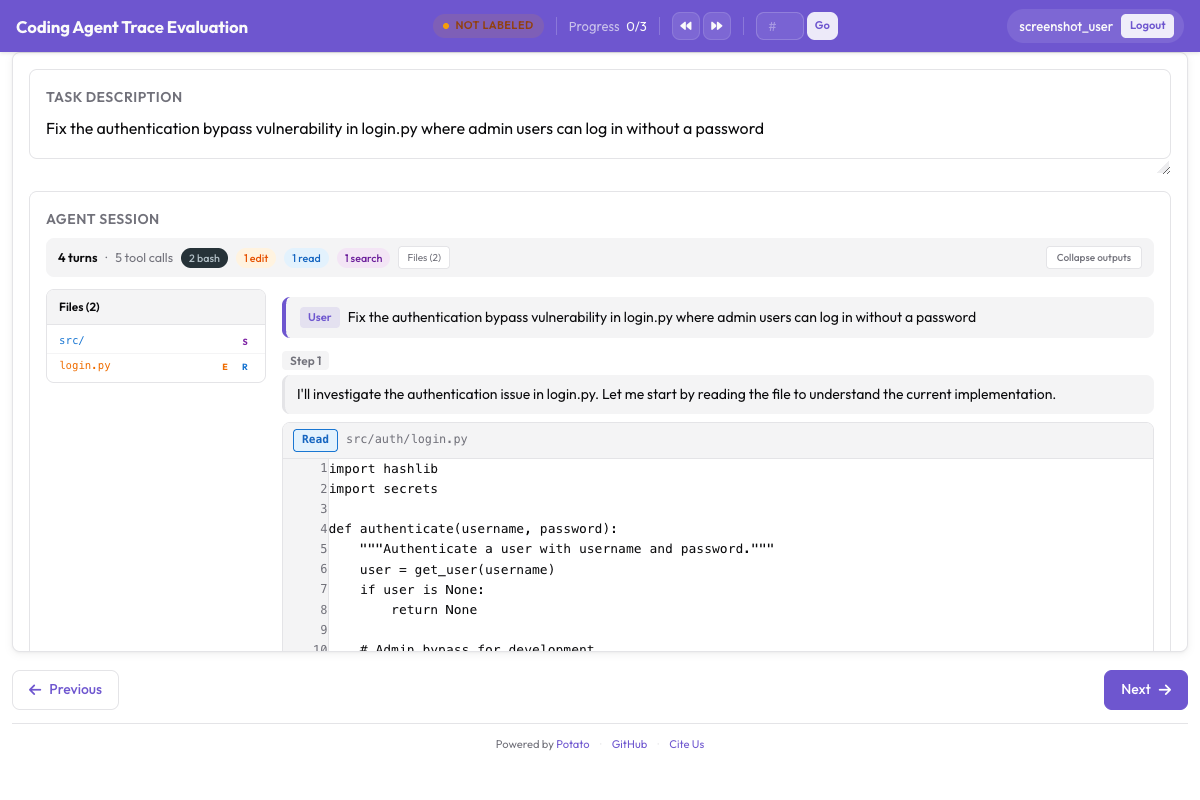 CodingTraceDisplay renders diffs, terminal blocks, and file reads alongside trajectory evaluation controls
CodingTraceDisplay renders diffs, terminal blocks, and file reads alongside trajectory evaluation controls
3. Launch the annotation server
potato start config.yaml -p 8000Open http://localhost:8000 in your browser. You will see the first trace with the step-by-step display.
4. Write annotation guidelines
Give annotators clear instructions. At a minimum, document:
- When to mark a step as incorrect vs. correct-but-suboptimal
- How to choose between error categories when multiple apply (use the most specific one)
- When to assign each severity level, with concrete examples
- Whether to evaluate steps based on information available at that step or with hindsight
The annotation workflow
When an annotator opens a trace, the task description sits at the top and the first step is below it. The running score reads 100 in the top-right corner.
For each step, the annotator:
- Reads the step content in context of previous steps
- Marks correctness by clicking "Correct" or "Incorrect"
- If incorrect, selects the error category (e.g., "Reasoning Error") and then the specific type (e.g., "Incorrect Assumption")
- Assigns severity: minor, major, or critical
- Writes a rationale (if enabled): "The agent assumes the file is in the current directory without checking, but the search results showed it is in src/utils/"
- Advances to the next step by clicking "Next Step" or pressing the right arrow key
The running score updates after each error. Mark step 3 as a major error (-5) and the score drops from 100 to 95. Mark step 7 critical (-10) and it falls to 85.
At the end of the trace, the annotator gives the overall success/partial/failure rating and submits.
Analyzing the results
Loading annotation data
import json
import pandas as pd
from collections import Counter
from pathlib import Path
# Load all annotation files
annotations = []
output_dir = Path("output/")
for f in output_dir.glob("*.jsonl"):
with open(f) as fh:
for line in fh:
annotations.append(json.loads(line))
print(f"Loaded {len(annotations)} annotated traces")Error distribution analysis
# Extract all errors across all traces
errors = []
for ann in annotations:
for step_ann in ann.get("error_localization", []):
if step_ann["correctness"] == "incorrect":
errors.append({
"trace_id": ann["trace_id"],
"step_index": step_ann["step_index"],
"category": step_ann["error_category"],
"error_type": step_ann["error_type"],
"severity": step_ann["severity"],
"rationale": step_ann.get("rationale", ""),
})
error_df = pd.DataFrame(errors)
print(f"Total errors found: {len(error_df)}")
print()
# Error distribution by category
print("Errors by category:")
print(error_df["category"].value_counts())
print()
# Most common specific error types
print("Top 10 error types:")
print(error_df["error_type"].value_counts().head(10))
print()
# Severity distribution
print("Severity distribution:")
print(error_df["severity"].value_counts())Error position analysis
Seeing where in a trace errors tend to land often reveals systematic patterns:
import matplotlib.pyplot as plt
import numpy as np
# Normalize step positions to [0, 1] range
for ann in annotations:
trace_length = len(ann.get("error_localization", []))
for step_ann in ann["error_localization"]:
if step_ann["correctness"] == "incorrect":
step_ann["normalized_position"] = step_ann["step_index"] / max(trace_length - 1, 1)
# Collect normalized positions
positions = [
step_ann["normalized_position"]
for ann in annotations
for step_ann in ann.get("error_localization", [])
if step_ann["correctness"] == "incorrect"
and "normalized_position" in step_ann
]
plt.figure(figsize=(10, 4))
plt.hist(positions, bins=20, edgecolor="black", alpha=0.7)
plt.xlabel("Normalized Position in Trace (0 = start, 1 = end)")
plt.ylabel("Error Count")
plt.title("Where Do Agent Errors Occur?")
plt.tight_layout()
plt.savefig("error_position_distribution.png", dpi=150)
print("Saved error_position_distribution.png")Running score distributions
# Extract final running scores
final_scores = []
for ann in annotations:
score = 100
severity_weights = {"minor": -1, "major": -5, "critical": -10}
for step_ann in ann.get("error_localization", []):
if step_ann["correctness"] == "incorrect":
score += severity_weights.get(step_ann["severity"], 0)
score = max(score, 0)
final_scores.append({
"trace_id": ann["trace_id"],
"final_score": score,
"overall_success": ann.get("overall_success", "unknown"),
})
score_df = pd.DataFrame(final_scores)
print("Score statistics:")
print(score_df["final_score"].describe())
print()
# Score distribution by overall success
for label in ["success", "partial", "failure"]:
subset = score_df[score_df["overall_success"] == label]
if len(subset) > 0:
print(f"{label}: mean={subset['final_score'].mean():.1f}, "
f"median={subset['final_score'].median():.1f}, "
f"n={len(subset)}")Most common failure modes
# Group errors by category + type for a failure mode analysis
failure_modes = (
error_df.groupby(["category", "error_type"])
.agg(
count=("severity", "size"),
avg_severity_weight=("severity", lambda x: x.map(
{"minor": 1, "major": 5, "critical": 10}
).mean()),
)
.sort_values("count", ascending=False)
)
print("Top failure modes (by frequency):")
print(failure_modes.head(15).to_string())
print()
# Impact-weighted failure modes (frequency x average severity)
failure_modes["impact"] = failure_modes["count"] * failure_modes["avg_severity_weight"]
print("Top failure modes (by impact):")
print(failure_modes.sort_values("impact", ascending=False).head(10).to_string())Research context
Per-step error localization lines up with a few recent threads in agent evaluation:
The TRAIL Benchmark (Patronus AI, 2025) pushed the idea of evaluating agent trajectories instead of just outcomes, and showed that agents fail in predictable patterns that outcome-level metrics miss entirely. The trajectory_eval schema is a way to collect those fine-grained step-level labels at scale.
AgentRewardBench set up benchmarks for process reward models (PRMs) that score individual reasoning steps. The step-level correctness and severity labels from trajectory_eval drop straight into PRM training: each annotated step is a training example with a ground-truth quality signal.
Anthropic's "Demystifying Evals for AI Agents" (2025) argued that agent evaluation should focus on trajectory quality, not just whether the final answer was right. The failure modes they call out (premature termination, tool misuse, reasoning errors) map directly onto the taxonomy categories in this guide.
The severity-weighted running score also maps onto the reward signals used in RLHF. A score curve that drops sharply at step 5 of a 20-step trace tells you exactly where the agent needs work, which is a lot more actionable than a single end-of-trace reward.
Summary
The trajectory_eval schema turns agent evaluation from a pass/fail check into a diagnostic. With a hierarchical taxonomy, severity scoring, and a running score, you can see which step went wrong, what kind of error it was, how bad it was, and where errors tend to cluster across traces. The step-level labels are also ready to use as process reward model training data.
Start with the full taxonomy in this guide, then refine it for your agent and the error patterns you actually see. The best taxonomy is the one that points at fixes you can make.