Toxicity Detection
Multi-label classification for identifying various types of toxic content including hate speech, threats, and harassment.
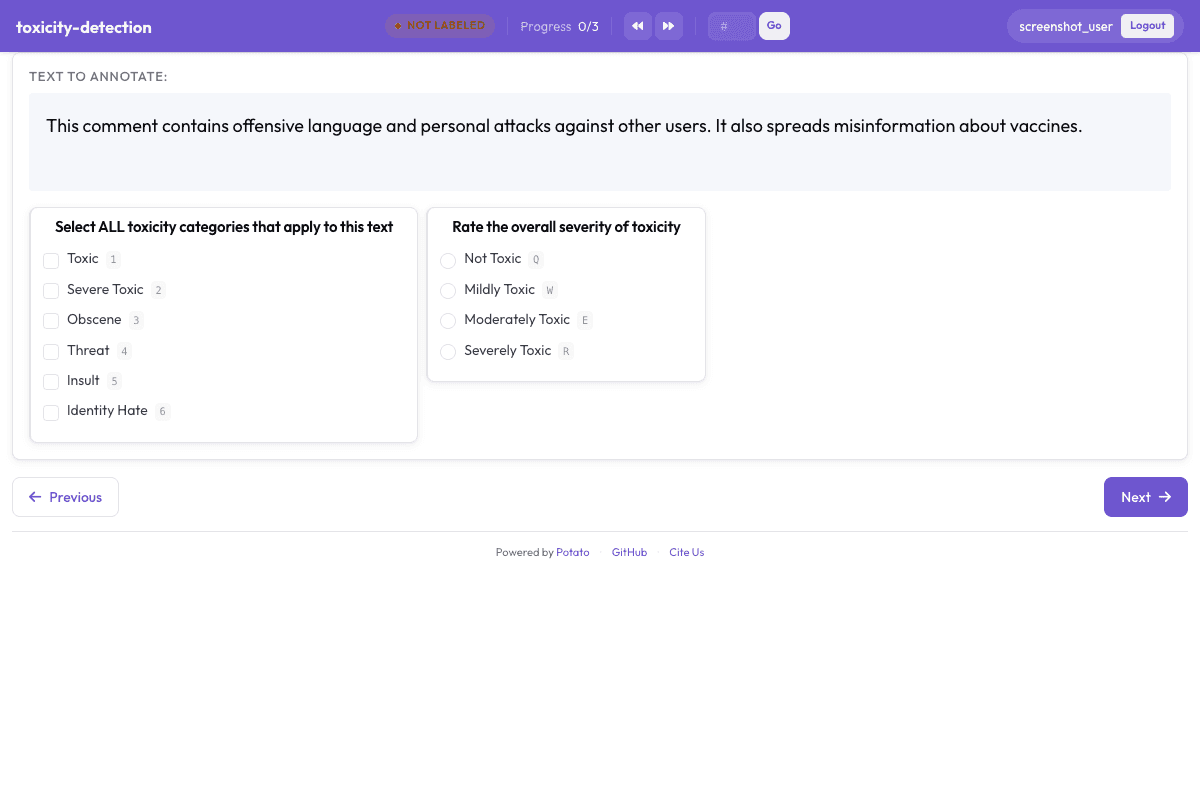
Configuration Fileconfig.yaml
# Toxicity Detection Configuration
# Generated by Potato Annotation Showcase
port: 8000
annotation_task_name: "Toxicity Detection"
task_dir: "."
# Data configuration
data_files:
- "data.json"
item_properties:
id_key: id
text_key: text
# Output
output_annotation_dir: "annotation_output/"
output_annotation_format: "json"
# Annotation schemes
annotation_schemes:
# Multi-label toxicity categories
- annotation_type: multiselect
name: toxicity_labels
description: "Select ALL toxicity categories that apply to this text"
labels:
- name: Toxic
key_value: "1"
- name: Severe Toxic
key_value: "2"
- name: Obscene
key_value: "3"
- name: Threat
key_value: "4"
- name: Insult
key_value: "5"
- name: Identity Hate
key_value: "6"
sequential_key_binding: true
tooltips:
Toxic: "Rude, disrespectful, or unreasonable content likely to make someone leave a discussion"
Severe Toxic: "Extremely hateful, aggressive, or disrespectful content"
Obscene: "Lewd, indecent, or profane language"
Threat: "Content that expresses intention to inflict harm"
Insult: "Insulting, inflammatory, or provocative content directed at a person"
Identity Hate: "Hateful content targeting someone's identity (race, religion, gender, etc.)"
# Overall severity rating
- annotation_type: radio
name: overall_severity
description: "Rate the overall severity of toxicity"
labels:
- name: Not Toxic
key_value: "q"
- name: Mildly Toxic
key_value: "w"
- name: Moderately Toxic
key_value: "e"
- name: Severely Toxic
key_value: "r"
sequential_key_binding: true
# User configuration
require_password: false
Get This Design
This design is available in our showcase. Copy the configuration below to get started.
Quick start:
# Create your project folder mkdir toxicity-detection cd toxicity-detection # Copy config.yaml from above potato start config.yaml
Details
Annotation Types
Domain
Use Cases
Tags
Related Designs
HateXplain - Explainable Hate Speech Detection
Multi-task hate speech annotation with classification (hate/offensive/normal), target community identification, and rationale span highlighting. Based on the HateXplain benchmark (Mathew et al., AAAI 2021) - the first dataset covering classification, target identification, and rationale extraction.
Toxic Spans Detection
Character-level toxic span annotation based on SemEval-2021 Task 5 (Pavlopoulos et al., 2021). Instead of binary toxicity classification, annotators identify the specific words/phrases that make a comment toxic, enabling more nuanced content moderation.
Dynamic Hate Speech Detection
Hate speech classification with fine-grained type labels based on the Dynamically Generated Hate Speech Dataset (Vidgen et al., ACL 2021). Classify content as hateful or not, then identify hate type (animosity, derogation, dehumanization, threatening, support for hateful entities) and target group.